Happy LLM - Datawhale
Happy LLM - Datawhale
第一章:NLP 基础概念
NLP 核⼼任务是通过计算机程序来模拟⼈类对语⾔的认知和使⽤过程
从符号主义与统计方法 到 机器学习与深度学习
任务包括但不限于中文分词、子词切分、词性标注、文本分类、实体识别、关系抽取、文本摘要、机器翻译以及自动问答系统的开发。
第二章:Transformer 架构
2.1 注意力机制
2.1.1 什么是注意力机制
从 CV 为起源发展起来的神经网络,其核心架构有三种:
前馈神经网络 Feedforward Neural Network, FNN;每层神经元之间完全链接;
卷积神经网络 Convolutional Neural Network, CNN:用训练参数量远小于 FNN 的卷积层来进行特征提取和学习;
循环神经网络 Recurrent Neural Network, RNN:能够用历史信息作为输入,包含环和自重复的网络;
过去常用 RNN,但 RNN 限制了计算机并行计算的能力,难以捕捉长序列的相关关系;
2.1.2 深入理解注意力机制
于是借鉴 CV 的注意力机制,有了 Transformer:
将重点注意力集中在一个或几个 token;
注意力机制有三个核心变量:Query(查询值)、Key(键值)和 Value(真值)。
注意力机制的特点是通过计算 Query 与 Key 的相关性为真值加权求和(注意力分数),从而拟合序列中每个词同其他词的相关关系。
2.1.3 注意力机制的实现
\[\begin{equation} attention(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V \label{eq:attention} \end{equation}\]其中,$ Q $ 与 $ K $ 相乘的结果反映了 $ query $ 与每一个 $ key $ 的相似程度,经 $ softmax $ 归一化,得到注意力分数。将其乘上 $ V $,得到最终值。
除以 $ \sqrt{d_k} $ 是为了避免 $ Q $ 与 $ K $ 对应的维度 $ d_k $ 较大,使得 $ softmax $ 放缩时受过多影响,使不同值之间的差异较大,影响梯度的稳定性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import torch
import math
def attention(query, key, value, dropout = None):
# query [batch, seq_len_q, dim]
# key [batch, seq_len_k, dim]
d_k = query.size(-1) # 获取特征 dim
# matmul 矩阵计算
# transpose 使得 q 与 k 能相乘
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# scores [batch, seq_len_q, seq_len_k]
# softmax 使得 seq_len_k 的值归一化
p_attn = scores.softmax(dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
2.1.4 自注意力机制 Self-attention
- 在 Transformer 的 Encoder 的,我们希望获取每一个 token 对其它 token 的注意力分布,就有了自注意力机制(Self-attention)
1
attention(x, x, x)
2.1.5 掩码自注意力机制 Mask Self-attention
- 让模型只能看到历史信息而看不到未来信息,需要用 [mask] 来遮蔽未来的信息
1
2
3
4
5
<BOS> [MASK] [MASK] [MASK] [MASK],
<BOS> I [MASK] [MASK] [MASK],
<BOS> I like [MASK] [MASK],
<BOS> I like you [MASK],
<BOS> I like you </EOS>
- 掩码矩阵就是一个跟文本序列等长的上三角矩阵,当输入维度为 (batch_size, seq_len, hidden_size)时,我们的 Mask 矩阵维度一般为 (1, seq_len, seq_len)(通过广播实现同一个 batch 中不同样本的计算)。
1
2
3
4
5
6
7
8
9
10
11
# 掩码矩阵
mask = torch.full((1, args.max_seq_len, args.max_seq_len), float("-inf"))
# diagonal = 1 使得只保留对角线上的元素,若 = 0 则保留对角线元素;除上三角地区为 -inf 外,其它元素均为 0
mask = torch.triu(mask, diagonal = 1)
# 把负无穷掩码加上 softmax 对极大极小值敏感,-inf 概率会趋近于 0,实现屏蔽未来位置的注意力
scores = scores + mask[:, :seqlen, :seqlen]
# 最后一维归一化 使得类型同 xq
scores = F.softmax(scores.float(), dim = -1).type_as(xq)
2.1.6 多头注意力机制 Multi-Head attention
- 一次注意力计算只能拟合一种相关关系,单一的注意力机制很难全面拟合语句序列里的相关关系。因此 Transformer 使用了多头注意力机制,同时对一个语料进行多次注意力计算,每次注意力计算都能拟合不同的关系,将最后的多次结果拼接起来作为最后的输出
\(\begin{equation} \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h) W^O \label{eq:multi_head} \end{equation}\) 其中,$ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $
- 我们可以通过矩阵运算巧妙地实现并行的多头计算,其核心逻辑在于使用三个组合矩阵来代替了 n 个参数矩阵的组合,也就是矩阵内积再拼接其实等同于拼接矩阵再内积。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
import torch.nn as nn
import torch
import torch.nn.functional as F
import math
class ModelArgs:
def __init__(self,
n_embd=768,
n_heads=12,
dim=768,
dropout=0.1,
max_seq_len=2048,
model_parallel_size=1):
self.n_embd = n_embd
self.n_heads = n_heads
self.dim = dim
self.dropout = dropout
self.max_seq_len = max_seq_len
self.model_parallel_size = model_parallel_size
class MultiHeadAttention(nn.Module):
def __init__(self, args: ModelArgs, is_causal = False):
super().__init__()
# 隐藏层维度必须是头数的整数倍 后面我们会将输入拆成头数个矩阵
assert args.n_embd % args.n_heads == 0, "隐藏层维度必须是头数的整数倍"
# 模型并行处理大小
model_parallel_size = 1
# 本地计算头数
self.n_local_heads = args.n_heads // model_parallel_size
# 每个头的维度
self.head_dim = args.dim // args.n_heads
# Wq Wk Wv 三个参数矩阵 [n_embd * n_embd]
# 三个组合矩阵来代替了 n 个参数矩阵的组合,矩阵内积再拼接相当于拼接矩阵再内积
# 将输入维度 args.dim 投影到多头维度 args.n_heads * self.head_dim
self.wq = nn.Linear(args.dim, args.n_local_heads * self.head_dim, bias = False)
self.wk = nn.Linear(args.dim, args.n_local_heads * self.head_dim, bias = False)
self.wv = nn.Linear(args.dim, args.n_local_heads * self.head_dim, bias = False)
# 输出权重矩阵 [n_embd * n_embd] head_dim = n_embds / n_heads
self.wo = nn.Linear(args.n_local_heads * self.head_dim, args.dim, bias = False)
# 注意力与残差连接的 dropout
self.attn_dropout = nn.Dropout(args.dropout)
self.resid_dropout = nn.Dropout(args.dropout)
self.is_causal = is_causal
# 一个上三角矩阵 mask 掩码
# 在多头注意力下 mask 矩阵要比之前我们定义的多一个维度
if self.is_causal:
mask = torch.full((1, 1, args.max_seq_len, args.max_seq_len), float("-inf"))
mask = torch.triu(mask, diagonal = 1)
# 注册为模型的缓冲区
# 缓冲区是一种特殊的张量,缓冲区不会被视为需要优化的参数,不会在反向传播中更新
# 但仍随模型保存 通常用于固定数据
self.register_buffer("mask", mask)
def forward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
# 获取批次大小和序列长度 [batch_size, seq_len, dim]
batch_size, seqlen, _ = q.shape
# 计算查询(Q)、键(K)、值(V),输⼊通过参数矩阵层,维度为 (B, T, n_embed) x (n_embed, n_embed) -> (B, T, n_embed)
xq, xk, xv = self.wq(q), self.wk(k), self.wv(v)
# [batch_size, seq_len, hidden_dim]
# -> [batch_size, seq_len, n_local_heads, head_dim]
# -> [batch_size, n_local_heads, seq_len, head_dim]
xq = xq.view(batch_size, seqlen, self.n_local_heads, self.head_dim).transpose(1, 2)
xk = xk.view(batch_size, seqlen, self.n_local_heads, self.head_dim).transpose(1, 2)
xv = xv.view(batch_size, seqlen, self.n_local_heads, self.head_dim).transpose(1, 2)
# 注意力计算
# [B, nh, T, hs] * [B, nh, hs, T] -> [B, nh, T, T]
scores = torch.matmul(xq, xk.transpose(2, 3)) / math.sqrt(self.n_local_heads)
# 若为掩码 有
if self.is_causal:
assert hasattr(self, 'mask'), "不存在掩码"
scores = scores + self.mask[:, :, :seqlen, :seqlen]
# softmax [B, nh, T, T] 后 dropout
scores = F.softmax(scores.float(), dim = -1).type_as(xq)
scores = self.attn_dropout(scores)
# scores * V
# [B, nh, T, T] * [B, nh, T, hs] -> [B, nh, T, hs]
output = torch.matmul(scores, xv)
# 恢复时间维度并合并头
# 将多头的结果拼接起来 C = n_local_heads × head_dim, C 即隐藏层维度 hidden_dim
# [B, T, n_local_heads, C // n_local_heads] -> [B, T, n_local_heads * C // n_local_heads]
# contiguous 函数用于重新开辟一块新内存存储,因为 Pytorch 设置先 transpose 再 view 会报错,
# 因为 view 直接基于底层存储得到,然而 transpose 并不会改变底层存储,因此需要额外存储
# view(bsz, seqlen, -1) 会保持张量元素总数不变,将张量重新组织成 [bsz, seqlen, ...] 的形状:
output = output.transpose(1, 2).contiguous().view(batch_size, seqlen, -1)
# 投影回残差流
output = self.wo(output)
output = self.resid_dropout(output)
return output
2.2 Encoder - Decoder
2.2.1 Seq2Seq 模型
在 Transformer 中,使用注意力机制的是其两个核心组件 —— Encoder(编码器)和 Decoder(解码器)
所谓编码,就是将输入的自然语言序列通过隐藏层编码成能够表征语义的向量(或矩阵),可以简单理解为更复杂的词向量表示。而解码,就是对输入的自然语言序列编码得到的向量或矩阵通过隐藏层输出,再解码成对应的自然语言目标序列。
Seq2Seq 是 NLP 最经典的任务,几乎所有的 NLP 任务都可以视为 Seq2Seq 任务。
Transformer 由 Encoder 和 Decoder 组成,每一个 Encoder(Decorder)又由 6 个 Encoder(Decoder)Layer 组成。输入源序列会进入 Encoder 进行编码,到 Encoder Layer 的最顶层再将编码结果输出给 Decoder Layer 的每一层,通过 Decoder 解码后就可以得到输出目标序列了
2.2.2 前馈神经网络 Feed Forward Neural Network
- Transformer 中的 FFN 步骤:$ w1 -> relu -> w2 -> dropout $
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import torch
import torch.nn as nn
import torch.nn.functional as F
class MLP(nn.Module):
def __init__(self, dim : int, hidden_dim : int, dropout : float):
super.__init__()
self.w1 = nn.Linear(dim, hidden_dim, bias = False)
self.w2 = nn.Linear(hidden_dim, dim, bias = False)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# w1 -> relu -> w2 -> dropout
return self.dropout(self.w2(F.relu(self.w1(x))))
2.2.3 层归一化 Layer Norm
假设输入是一个批次的图像 $ [batchsize, channels, height, width] $:
BN:对每个通道(如 RGB 通道),计算所有样本在该通道上的均值和方差,然后归一化。同一特征列的不同样本被归一化(跨样本),不同特征列独立计算。
LN:对每个图像单独计算所有通道的均值和方差,然后归一化。同一样本内的所有特征被归一化(样本内),不同样本独立计算。
假设一个批次 $ [batchsize=2, features=3] $,
- BN 结果为(特征列被归一化)
- LN 结果为(样本行被归一化)
归一化公式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class LayerNorm(nn.Module):
def __init__(self, features, eps = 1e-6):
super(LayerNorm, self).__init__()
# nn.Parameter 会将张量注册为模块的可学习参数,反向传播时会自动更新
# 初始值为形状 [features] 的全 1 张量,归一化后缩放分布
self.a_2 = nn.Parameter(torch.ones(features))
# 初始值为形状 [features] 的全 0 张量,归一化后偏移分布
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
# mean std 形状为 [bsz, max_len, 1]
# keepdim 会保留指定的维度,而不是丢弃,若丢弃则变为 [bsz, max_len]
mean = x.mean(-1, keepdim = True)
std = x.std(-1, keepdim = True)
# 最后一维为 1,进行了广播
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
2.2.4 残差连接
由于 Transformer 模型结构较复杂、层数较深,为了避免模型退化,Transformer 采用了残差连接的思想来连接每一个子层。
残差连接,即下一层的输入不仅是上一层的输出,还包括上一层的输入。残差连接允许最底层信息直接传到最高层,让高层专注于残差的学习。
1
2
h = x + self.attention.forward(self.attention_norm(x))
output = h + self.feed_forward.forward(self.fnn_norm(h))
2.2.5 Encoder 编码器
Encoder 由 N 个 Encoder Layer 组成,每一个 Encoder Layer 包括一个多头自注意力层和一个前馈神经网络。
一个 Encoder Layer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class EncoderLayer(nn.Module):
def __init__(self, args):
super().__init__()
# 一个 Layer 中有两个 norm,分别在 attention 与 MLP 之前
self.attention_norm = LayerNorm(features = args.n_embd)
# Encoder 不需要掩码
self.attention = MultiHeadAttention(args, is_causal = False)
self.fnn_norm = LayerNorm(features = args.n_embd)
self.feed_forward = MLP(args)
def forward(self, x):
# Layer Norm
norm_x = self.attention_norm(x)
# 自注意力层
h = x + self.attention.forward(norm_x, norm_x, norm_x)
# 经过前馈
output = h + self.feed_forward.forward(self.fnn_norm(h))
return output
- 若干 Encoder Layer 组成一个 Encoder:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Encoder(nn.Module):
def __init__(self, args):
super(Encoder, self).__init__()
self.layers = nn.ModuleList([EncoderLayer(args) for _ in range(args.n_layer)])
self.norm = LayerNorm(args.n_embd)
def forward(self, x):
# 分别通过 N 层 Encoder Layer
for layer in self.layers:
x = layer(x)
return self.norm(x)
2.2.6 Decoder 解码器
N 个 Decoder Layer 组装为 Decoder,Decoder 由两个注意力层和一个前馈神经网络组成。
第一个注意力层是一个掩码自注意力层;
第二个注意力层是一个多头注意力层,该层将使用第一个注意力层的输出作为 query,使用 Encoder 的输出作为 key 和 value,来计算注意力分数。
最后,再经过前馈神经网络:
一个 Decoder Layer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
class DecoderLayer(nn.Module):
def __init__(self, args):
super().__init__()
self.attention_norm1 = LayerNorm(args.n_embd)
self.mask_attetion = MultiHeadAttention(args, is_causal=True)
self.attention_norm2 = LayerNorm(args.n_embd)
self.attention = MultiHeadAttention(args, is_causal=False)
self.ffn_norm = LayerNorm(args.n_embd)
self.feed_forward = MLP(args)
def forward(self, x, encoder_output):
# 掩码自注意力
norm_x = self.attention_norm1(x)
x = x + self.mask_attetion.forward(norm_x, norm_x, norm_x)
# 多头注意力
norm_x = self.attention_norm2(x)
h = x + self.attention.forward(norm_x, encoder_output, encoder_output)
# 前馈
output = h + self.feed_forward.forward(self.ffn_norm(h))
return output
- 若干个 Decoder Layer 组成一个 Decoder:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Decoder(nn.Module):
def __init__(self, args):
super(Decoder, self).__init__()
self.layers = nn.ModuleList([DecoderLayer(args) for _ in range(args.n_layer)])
self.norm = LayerNorm(args.n_embd)
def forward(self, x, encoder_output):
for layer in self.layers:
x = layer(x, encoder_output)
return self.norm(x)
Encoder Layer 为 多头自注意力 + 前馈;Decoder Layer 为 掩码多头自注意力 + 编码解码交叉多头注意力 + 前馈。
2.3 搭建一个 Transformer
2.3.1 Embedding 层
自然语言通过分词器 tokenizer,切分成 token 并转化为一个固定的 index。
Embedding 层负责将自然语言的输入转化为机器可以处理的向量。Embedding 层其实是一个存储固定大小的词典的嵌入向量查找表。Embedding 层的输入往往是一个形状为 $ [batchsize, seqlen, 1] $ 的矩阵。其中最后一层的维度为 1,代表已经转换好的 index。
1
2
3
4
5
6
7
self.tok_embeddings = nn.Embedding(args.vocab_size, args.dim)
# num_embeddings:词汇表大小(即词表中唯一词的数量)
# embedding_dim:每个词向量的维度
# 创建一个包含1000个词、每个词用50维向量表示的嵌入层
embedding = nn.Embedding(num_embeddings=1000, embedding_dim=50)
2.3.2 位置编码
- 注意力机制可以实现良好的并行计算,但也导致序列中相对位置的丢失。对于序列中的每一个 token,其他各个位置对其来说都是平等的。故引入位置编码来进行编码,再将位置编码加入原先的词向量编码中。
- Transformer 使用了正余弦函数来进行位置编码(绝对位置编码 Sinusoidal),其编码方式为:
- numpy 即可快速实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import numpy as np
def PositionEncoding(seq_len, d_model, n = 10000):
P = np.zeros((seq_len, d_model))
for k in range(seq_len):
for i in np.arange(int(d_model / 2)):
denominator = np.power(n, 2 * i / d_model)
P[k, 2 * i] = np.sin(k / denominator)
P[k, 2 * i + 1] = np.cos(k / denominator)
return P
P = PositionEncoding(seq_len = 4, d_model = 4, n = 100)
print(P)
'''
[[ 0. 1. 0. 1. ]
[ 0.84147098 0.54030231 0.09983342 0.99500417]
[ 0.90929743 -0.41614684 0.19866933 0.98006658]
[ 0.14112001 -0.9899925 0.29552021 0.95533649]]
'''
绝对位置编码 Sinusoidal 的好处:
使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到,三角函数易得。
基于以上原理,实现一个位置编码层:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class PositionalEncoding(nn.Module):
def __init__(self, args):
super().__init__()
self.dropout = nn.Dropout(p = args.dropout)
# block_size 是序列的最大长度
pe = torch.zeros(args.block_size, args.n_embd)
# unsqueeze(1) 在维度 1 上增加一个维度,使其形状变为 [args.block_size, 1]
position = torch.arange(0, args.block_size).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, args.n_embd, 2) * -(math.log(10000.0) / args.n_embd)
)
# 分别计算 sin cos 结果
pe[:, 0::2] = torch.sin(position / div_term)
pe[:, 1::2] = torch.cos(position / div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
# [batch_size, seq_len, ...]
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
- 注:其中存在数学变化:
2.3.3 一个完整的 Transformer
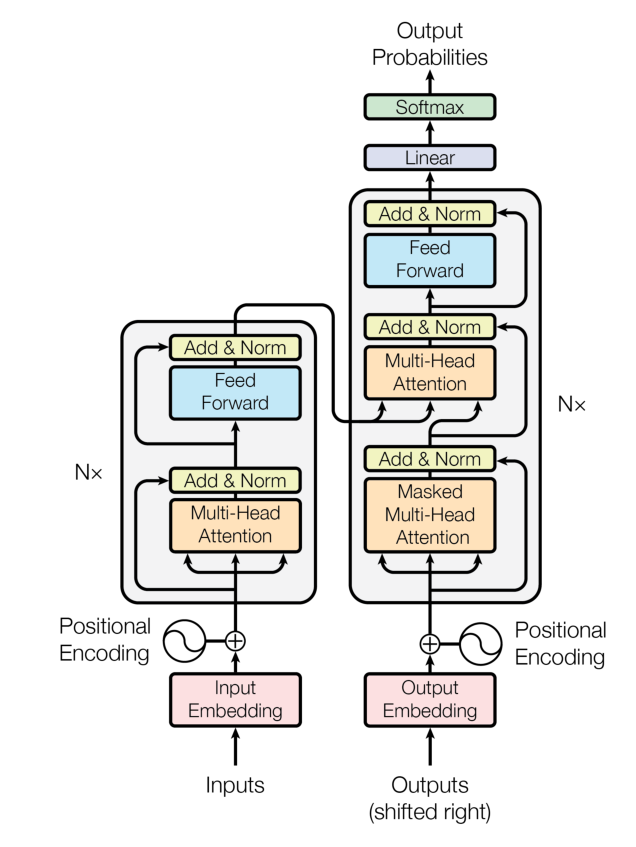
上图是原论文 Attention is all you need 配图,LayerNorm 层放在了 Attention 层后面,也就是“Post-Norm”结构。
但在其发布的源代码中,LayerNorm 层是放在 Attention 层前面的,也就是“Pre Norm”结构。
考虑到目前 LLM 一般采用“Pre-Norm”结构(可以使 loss 更稳定),本文在实现时采用“Pre-Norm”结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
class Transformer(nn.Module):
'''整体模型'''
def __init__(self, args):
super().__init__()
# 必须输入词表大小和 block size
assert args.vocab_size is not None, "vocab_size should not be None!"
assert args.block_size is not None, "block_size should not be None!"
self.args = args
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(args.vocab_size, args.n_embd),
wpe = PositionalEncoding(args),
drop = nn.Dropout(args.dropout),
encoder = Encoder(args),
decoder = Decoder(args),
))
# 最后的线性层 n_embd -> vocab_size
self.lm_head = nn.Linear(args.n_embd, args.vocab_size, bias = False)
# 初始化所有权重
# self.apply(fn)是nn.Module提供的一个重要方法。这个方法的作用是递归地将函数fn应用到当前模块及其所有子模块上
self.apply(self._init_weights)
# 查看所有参数的数量
print("number of parameters : %.2fM" % (self.get_num_params() / 1e6))
'''统计所有参数的数量'''
def get_num_params(self, non_embedding = False):
# non_embedding: 是否统计 embedding 的参数
# numel() 是张量 Tensor 的一个方法,用于返回张量中元素的总数,每个参数(如权重矩阵、偏置向量)都是一个张量
n_params = sum(p.numel() for p in self.parameters())
# 若不统计 embedding 就减去
if non_embedding:
n_params -= self.transformer.wpe.weight.numel()
return n_params
'''初始化权重'''
def _init_weights(self, module):
# 线性层和 Embedding 层初始化为正则分布
if isinstance(module, nn.Linear):
nn.init.normal_(module.weight, mean = 0.0, std = 0.02)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, mean = 0.0, std = 0.02)
# isinstance() 是一个内置函数,isinstance(object, classinfo),
# 如果 object 是 classinfo 的实例或子类实例,返回 True,否则返回 False
# self.parameters() 返回一个生成器(Generator),遍历模型中所有可训练参数(即需要计算梯度的 nn.Parameter 对象)。
'''前向计算函数'''
def forward(self, idx, targets = None):
# 输入为 idx,维度为 [batch_size, seq_len, 1];
# targets 为目标序列,用于计算 loss
device = idx.device
b, t = idx.size()
assert t <= self.args.block_size, f"不能计算该序列,该序列长度为 {t}, 最大序列长度只有 {self.args.block_size}"
# 通过 self.transformer
print("idx", idx.size())
# idx -> Embedding 层,[batch_size, seq_len, n_embd]
tok_emb = self.transformer.wte(idx)
print("tok_emb", tok_emb.size())
# -> 位置编码层
pos_emb = self.transformer.wpe(tok_emb)
# -> Dropout
x = self.transformer.drop(pos_emb)
# -> Encoder
print("x after wpe:", x.size())
encoder_out = self.transformer.encoder(x)
print("encoder_out:", encoder_out.size())
# -> Decoder
x = self.transformer.decoder(x, encoder_out)
print("x after decoder:", x.size())
if targets is not None:
# 训练阶段,如果我们给了 targets,就计算 loss
# 先通过最后的 Linear 层,得到维度为 [batch_size, seq_len, vocab_size]
logits = self.lm_head(x)
# 与 targets 计算交叉熵
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index = -1)
else:
# 推理阶段,我们只需要 logits,loss 为 None
# 取 -1 是只取序列中的最后一个作为输出
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, loss
如果在继承了
nn.Module的类中定义了forward(),可以通过model(x)来直接调用forward(),而无需显式调用forward()
self.apply(fn)是nn.Module提供的一个重要方法。这个方法的作用是递归地将函数fn应用到当前模块及其所有子模块上
self.parameters()返回Generator,遍历模型中所有可训练参数(即需要计算梯度的nn.Parameter对象)。
第三章:预训练语言模型
3.1 Encoder-only PLM(Pretrained LM)
- 针对 Encoder、Decoder 的特点,引入 ELMo 的预训练思路,开始出现不同的、对 Transformer 进行优化的思路。
3.1.1 BERT
BERT,全名为 Bidirectional Encoder Representations from Transformers,是由 Google 团队在 2018年发布的预训练语言模型。该模型发布于论文 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT 沿袭的核心思想包括:Transformer 与 预训练 + 微调 范式(2018年,ELMo 的诞生标志着预训练+微调范式的诞生)
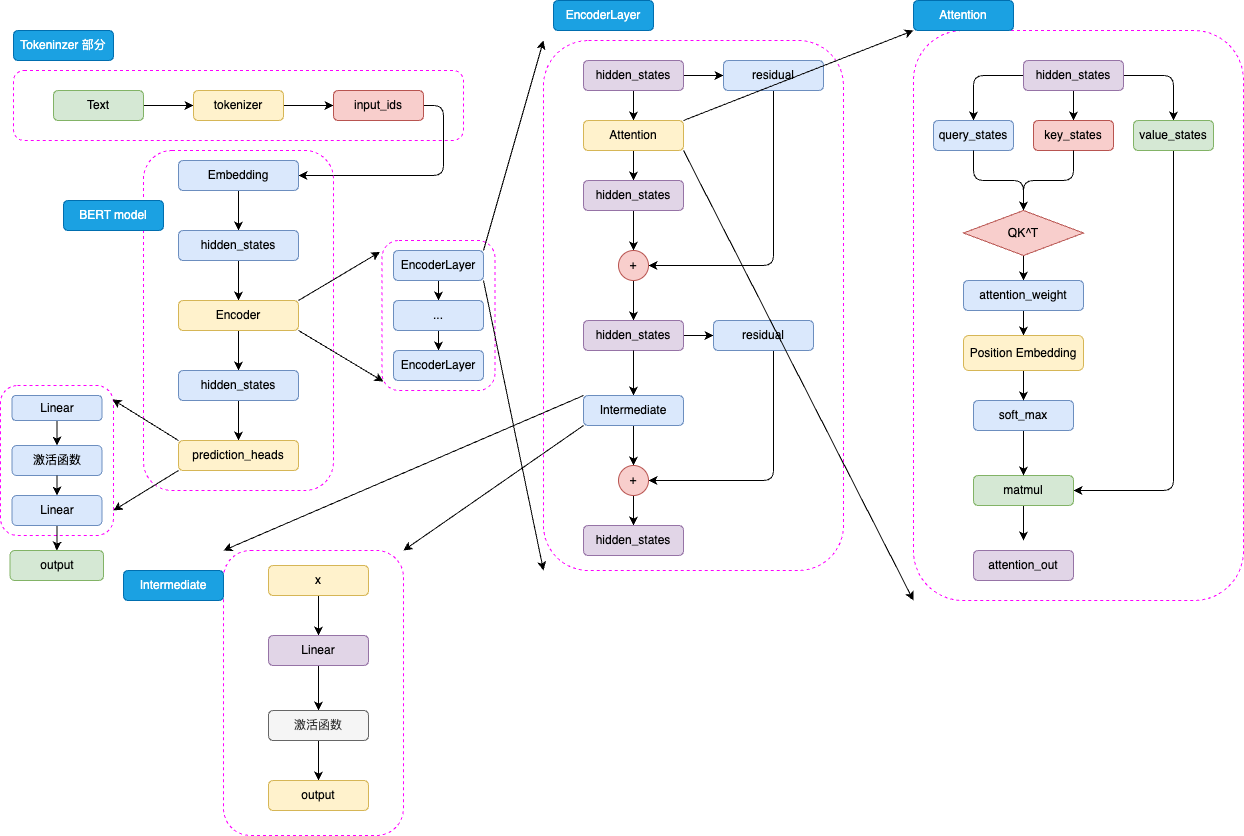
BERT 是针对于 NLU Natural Language Understanding 任务打造的预训练模型,输入为文本序列,输出是 label。
BERT = Embedding + Encoder + prediction_heads
为了让 Transformer 这个 Seq2seq 适配 NLU,故引入一个分类头 prediction_heads。
Prediction_heads = Linear + activation func + Linear
Encoder Layer 与 Transformer 中的 Encoder 类似
- Embedding + attention + 残差 + intermediate 层。Intermediate 层是 BERT 的特殊称呼,即 Linear + activation func
BERT 所用的激活函数是 GELU 函数,即“高斯误差线性单元激活函数”,这也是自 BERT 才开始被普遍关注的激活函数。
- GELU 的核心思路为将随机正则的思想引入激活函数,通过输入自身的概率分布,来决定抛弃还是保留自身的神经元。
在注意力机制处,BERT 将相对位置编码融合在了注意力机制中,将相对位置编码同样视为可训练的权重参数。
优点:可以拟合更丰富的相对位置信息
缺点:增加不少模型参数,无法处理超训练长度的输入
BERT 提出两大创新预训练任务:MLM(Masked Language Model)与 NSP(Next Sentence Prediction)
一次大规模预训练后,通过小规模微调即可应用在下游任务中
预训练数据的核心要求即是需要极大的数据规模,人工标记不显示,可通过遮蔽下文,使用上文预测下文即可。
缺点:拟合从左到右的语义关系,忽略了双向的语义关系
提出 MLM,其核心思路为:随机遮蔽部分 token,将未被遮蔽的 token 输入,预测被遮蔽的 token,例如:
1
2
输入:I <MASK> you because you are <MASK>
输出:<MASK> - love; <MASK> - wonderful
问题:但在下游任务微调和推理时,其实是不存在我们人工加入的
<MASK>的,预训练与微调不一致会影响模型微调性能解决办法:随机选择 15% 的 token 用于遮蔽;这 15% 的 token 中,有 80% 的概率被遮蔽,10% 的概率被替换为任意一个 token,还有 10% 的概率保持不变
原理:10% 保持不变是为了消除预训练和微调的不一致,而 10% 的随机替换核心意义在于迫使模型保持对上下文信息的学习。
保留 10% 的原 token,模型看到一个 token “苹果”,它既可能是原句中的正确 token,也可能是被 mask 后未替换的 token。
引入 10% 的随机替换后, “猫喜欢吃鱼” 中,“鱼” 被随机替换为 “狗”,模型看到的是 “猫喜欢吃狗”,此时它需要判断 “狗” 是否合理。
另一个预训练任务 NSP
针对句级的 NLU 任务,如问答匹配、自然语言推理等;用来训练模型在句级的语义关系拟合。
只需要从无监督语料中随机抽取连续句子或打乱,即可做到。
1
2
3
4
5
6
7
8
9
10
11
输入:
Sentence A:I love you.
Sentence B: Because you are wonderful.
输出:
1(是连续上下文)
输入:
Sentence A:I love you.
Sentence B: Because today's dinner is so nice.
输出:
0(不是连续上下文)
为了能够快速迁移到下游任务,BERT 设计了更通用的输入和输出层来适配多任务下的迁移学习。
对每一个输入的文本序列,BERT 会在其首部加入一个特殊 token
<CLS>。在后续编码中,该 token 代表的即是整句的状态,也就是句级的语义表征。<CLS>对应的输出向量会被模型 “训练” 成整个句子的全局语义表征,微调时只需拿<CLS>作为输入即可。
3.1.2 RoBERTa
优化思想:大即好。
优化1:去掉 NSP 与训练任务,并将 Mask 操作放到训练阶段,实现每一个 Epoch 得到训练数据 Mask 的位置都不一致,即动态遮蔽策略;
优化2:更大规模的预训练数据与预训练步长,成为 LLM 诞生的基础之一;
优化3:更大的 bpe 词表,Byte Pair Encoding,字节对编码,是指以子词对作为分词的单位。
3.1.3 ALBERT
优化思想:小而美。
优化1:将 Embedding 参数进行分解,在 Embedding 层的后面加入一个线性矩阵。Embedding 层的参数从 $ V * H $ 降低到了 $ V * E + E * H $。
优化2:跨层进行参数共享,让各个 Encoder 层共享模型参数,来减少模型的参数量。仅初始化一个 Encoder 层,实现进行 24 次计算,但只经过这一个 Encoder 层。
- 不足:训练与推理速度相较 BERT 更慢,这也是 ALBERT 最终没能取代 BERT 的一个重要原因。
优化3:提出 SOP 预训练任务(Sentence-Order Prediction),即在 NSP 任务基础上打乱基础,学习其顺序关系。
1
2
3
4
5
6
7
8
9
10
11
输入:
Sentence A:I love you.
Sentence B: Because you are wonderful.
输出:
1(正样本)
输入:
Sentence A:Because you are wonderful.
Sentence B: I love you.
输出:
0(负样本)
3.2 Encoder-Decoder PLM
3.2.1 T5(Text-To-Text Transfer Transformer)
T5 是由 Google 提出的一种 PLM,将所有 NLP 任务统一表示为文本到文本的转换问题。
模型架构:Encoder-Decoder
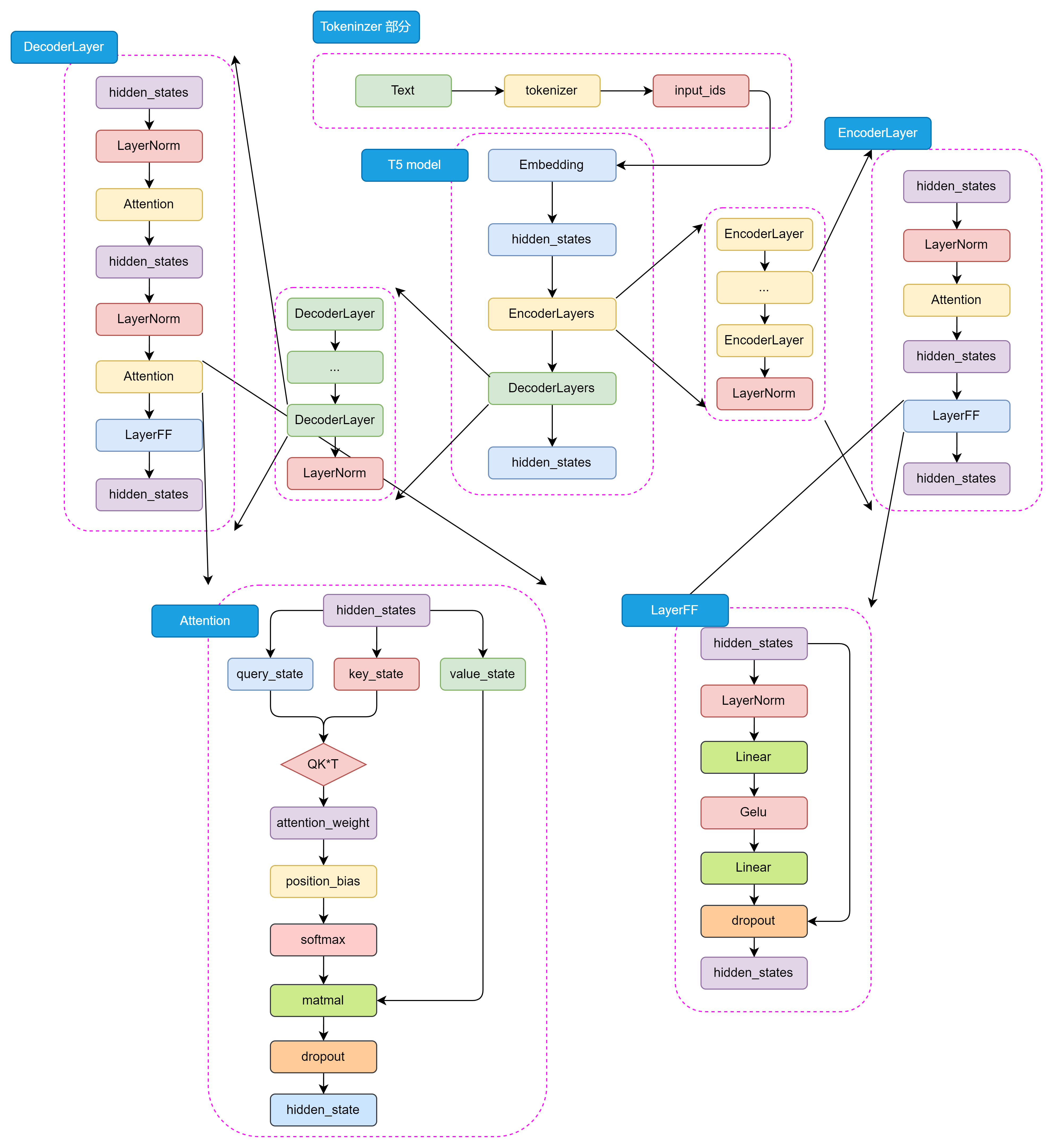
Transformer 部分又分为 EncoderLayers 和 DecoderLayers 两部分,分别由一个个小的 Block 组成,每个 Block 包含多头注意力机制、前馈和 Norm 层,模型更加灵活。
T5 的 Self-Attention 机制与 BERT 的 Self-Attention 机制一样。
T5 的 LayerNorm 采用了 RMSNorm,通过计算每个神经元的均方根(Root Mean Square)来归一化每个隐藏层的激活值。仅一个可调参数,适应度更好,比 Layer Norm \eqref{eq:batch_norm_layer_norm_formula} 更简单,同时有助于通过确保权重的规模不会变得过大或过小来稳定学习过程。
其中:
$ x_i $ 是输入向量的第 $i$ 个元素
$ \gamma $ 是可学习的缩放参数
$ n $ 是输入向量的维度数量
$ \epsilon $ 是一个小常数,用于数值稳定性(以避免除以零的情况)
预训练任务:
- T5 的预训练任务是 MLM,也成为 BERT-style 目标(遮蔽 15% 的 token……)
大一统思想:
设计理念是将所有不同类型的 NLP 任务转换为一个统一的格式:输入和输出都是纯文本。其思想影响深远。
其预训练 + 微调的方式与 BERT、GPT 类似,但文本到文本的形式使得其适应性更强。
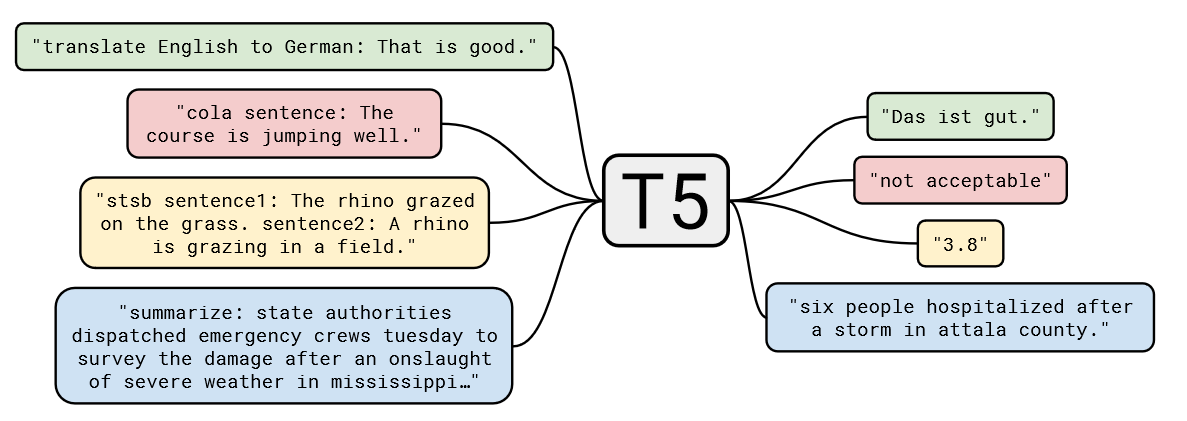
对于不同的 NLP 任务,每次输入前都会加上一个任务描述前缀,明确指定当前任务的类型。有利于模型在预训练阶段学习到不同任务之间的通用特征,也便于在微调阶段迅速适应具体任务。
3.3 Decoder-Only PLM
- Decoder-Only 就是目前大火的 LLM 的基础架构,目前所有的 LLM 基本都是 Decoder-Only 模型(RWKV、Mamba 等非 Transformer 架构除外)。
3.3.1 GPT(Generative Pre-Training Language Model)
GPT 是由 OpenAI 团队于 2018 年发布的预训练语言模型。
BERT 是预训练语言模型时代的代表,而 GPT 首先明确提出了 预训练 - 微调 思想;
- 通用预训练:在海量无监督语料上预训练,进而在每个特定任务上进行微调
模型架构:Decoder Only
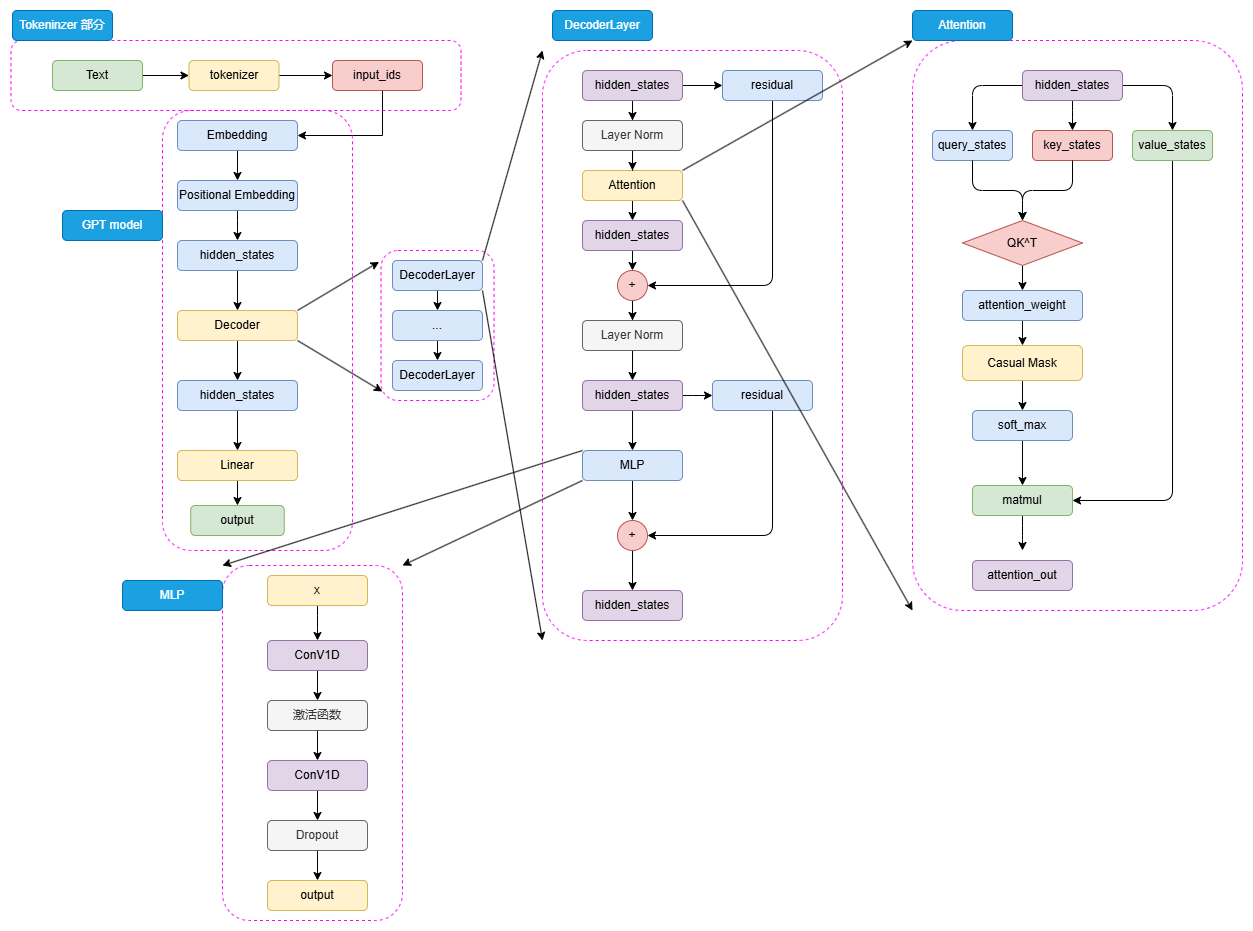
GPT 使用的是 Sinusoidal 位置编码,即通过三角函数进行绝对位置编码,参考 \eqref{eq:PE_Sinusoidal_sin} 和 \eqref{eq:PE_Sinusoidal_cos}。
GPT 的 Decoder 层仅保留了一个掩码自注意力层,使用 Pre-Norm 归一化办法。
预训练任务:CLM(Casual Language Model)
其思路为基于前 N 个 token 来预测下一个 token。
CLM 是更直接的预训练任务,其天生和人类书写自然语言文本的习惯相契合,与下游任务直接匹配。
1
2
3
4
5
input: 今天天气
output: 今天天气很
input: 今天天气很
output:今天天气很好
GPT 系列模型发展:
核心思想:力大砖飞。
GPT-1 参数与 BERT 类似,但表现不如 BERT,这是 GPT 没有成为预训练语言模型时代的代表的原因。
GPT-2 以 zero-shot(零样本学习)为主要目标,同时从 Post-Norm 变为 Pre-Norm。
GPT-3 提出 few-shot(少样本学习),即在 prompt中增加 3~5个示例,来帮助模型理解,也被称为上下文学习(In-Context Learning),效果远好于 zero-shot,效率远高于传统的 预训练 - 微调 范式。
| 模型 | Decoder Layer | Hidden_size | 注意力头数 | 注意力维度 | 总参数量 | 预训练语料 |
|---|---|---|---|---|---|---|
| GPT-1 | 12 | 3072 | 12 | 768 | 0.12B | 5GB |
| GPT-2 | 48 | 6400 | 25 | 1600 | 1.5B | 40GB |
| GPT-3 | 96 | 49152 | 96 | 12288 | 175B | 570GB |
3.3.2 LLaMA
LLaMA 模型是由 Meta(前 Facebook)开发的一系列大型预训练语言模型。
模型架构:Decoder Only
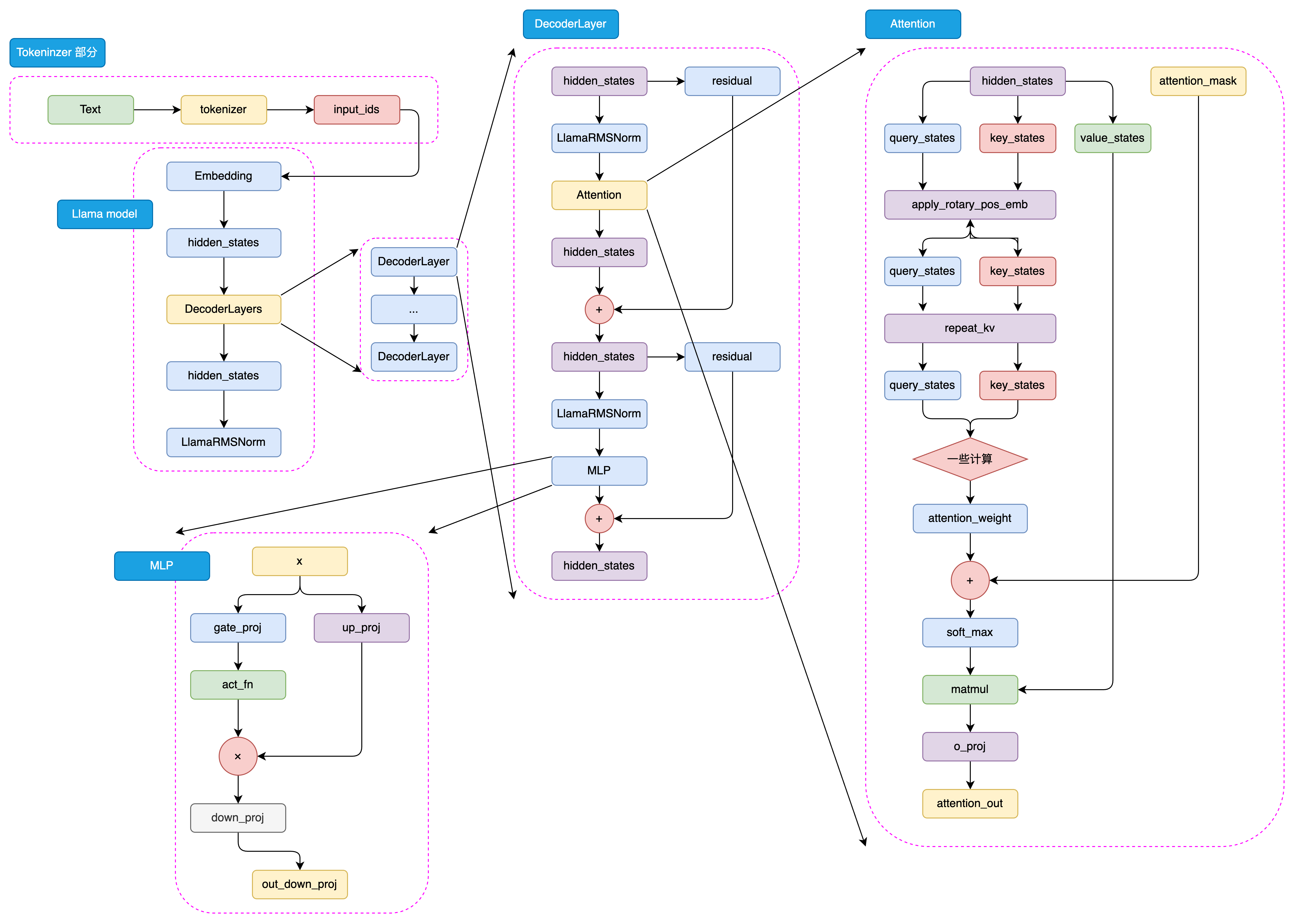
经过多个 decoder block 的处理,hidden_states 会通过一个线性层进行最终的映射,这个线性层的输出维度与词表维度相同。这样,模型就可以根据 hidden_states 生成目标序列的概率分布,进而通过采样或贪婪解码等方法,生成最终的输出序列。
LLaMA 模型的发展历程:
开源,技术创新、多参数版本、大规模预训练和高效架构设计;
LLaMA-2 和 LLaMA- 3进一步通过引入分组查询注意力机制;
训练数据大、词表大、支持长文本输入。
3.3.3 GLM(Generative Language Model)
在整体模型结构上,GLM 和 GPT 大致类似,均是 Decoder-Only 的结构,仅有三点细微差异:
使用 Post-Norm 而不是 Pre-Norm:Post Norm 在残差之后做归一化,对参数正则化的效果更强,模型的鲁棒性更好;Pre Norm 有一部分参数直接加在了后面,不需要对这部分参数进行正则化,正好可以防止模型的梯度爆炸或者梯度消失。主流 LLM 都用 Pre-Norm。
使用单个线性层实现最终 token 的预测,而不是使用 MLP;这样的结构更加简单也更加鲁棒,即减少了最终输出的参数量,将更大的参数量放在了模型本身;
激活函数从 ReLU 换成了 GeLU,参考 \eqref{eq:GELU}。
预训练任务 - GLM(Generative Language Model)
GLM 是一种结合了自编码思想和自回归思想的预训练方法。
自编码思想:MLM 的任务学习思路,在输入文本中随机删除连续的 tokens,要求模型学习被删除的 tokens;
自回归思想:传统 CLM 任务学习思路,要求模型按顺序重建连续 tokens。
GLM 通过优化一个自回归空白填充任务来实现 MLM 与 CLM 思想的结合:与 MLM 遮蔽单个 token 不同,GLM 选择遮蔽一连串 token。
既需要使用遮蔽部分的上下文预测遮蔽部分,在遮蔽部分内部又需要以 CLM 的方式完成被遮蔽的 tokens 的预测。
GLM 在预训练时代有优势,但在 LLM 时代,CLM 优势远超 MLM,从 ChatGLM2 开始,也回归了 CLM。
1
2
输入:I <MASK> because you <MASK>
输出:<MASK> - love you; <MASK> - are a wonderful person
GLM 家族发展
ChatGLM-6B:第一个中文开源 LLM;
ChatGML2-6B:上下文长度更长,更大预训练规模,回归 LLaMA 架构,引入 MQA(Multi-Query Attention)的注意力机制,回归 CLM 预训练任务;
ChatGLM3-6B:开始支持函数调用和代码解释器,可直接进行 Agent 开发;
ChatGLM4-9B:更大更好。
第四章:大语言模型
4.1 什么是 LLM
4.1.1 LLM 的定义
- 参数数百亿(B billion 十亿),数 T token 语料,有涌现能力。
4.1.2 LLM 的能力
涌现能力 Emergent Abilities
- 在同样的模型架构与预训练任务下,大模型的某些能力远超小型模型,超过了随机水平,量变引起质变。
上下文学习 In-context Learning
在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新。
微调对显存和训练样本仍有门槛要求,而 In-context Learning 可以大大节省。
通过调整 Prompt 或提供 1-5 个自然语言示例,就可以令 GPT-4 超过传统 PLM 微调。
指令遵循 Instruction Following
- IF 后的 LLM 可以理解并遵循未见指令执行任务,在同样使用指令形式化描述的未见过的任务上表现良好。泛化能力极强。
逐步推理 Step by Step Reasoning
LLM 通过思维链(Chain-of-Thought, CoT),揭示包含中间推理步骤的提示机制。
这种能力可能是通过对代码的训练获得的。
4.1.3 LLM 的特点
多语言支持
- 预训练语料天然给 LLM 带来多语言能力。但需注意,这跟语料关系很大;如英文高质量语料占大部分,这使得 GPT-4 英文能力远超中文能力。
长文本处理
在海量分布式训练集群上训练,LLM 在训练时就支持 4K 8K 32K 等上下文长度;
可以使用旋转位置编码(Rotary Positional Encoding, RoPE),使得 LLM 具有长度外推能力,推理时能够处理显著长于训练长度的文本。
拓展多模态
- 可以增加额外的参数;引入 Adapter 层和图像编码器,并针对性地在图文数据上进行有监督微调。
幻觉
- 瞎编乱编;提示词工程和 RAG 只能减弱幻觉而无法彻底根除。
4.2 如何训练一个 LLM
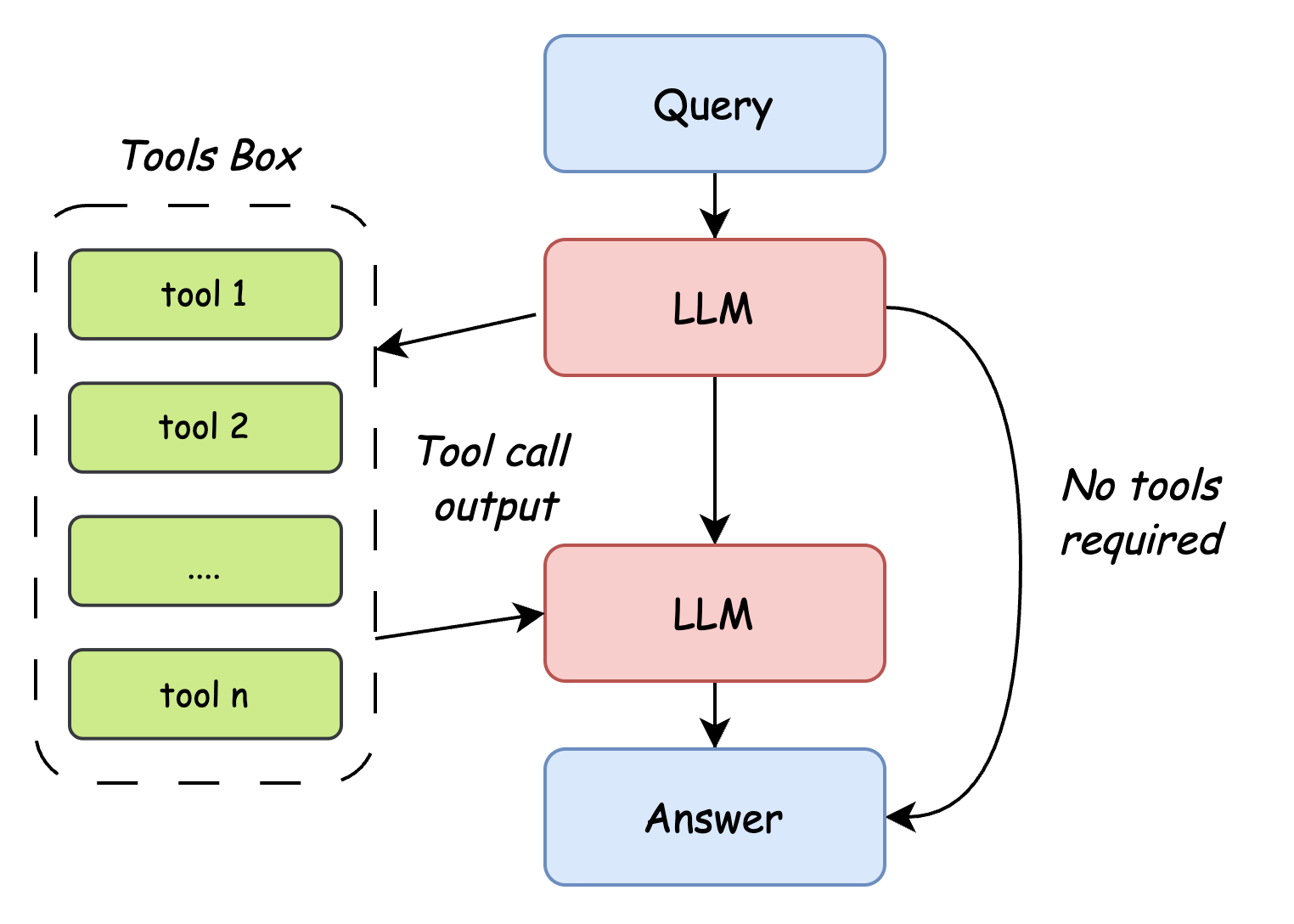
训练 LLM 的三个阶段,如图所示:
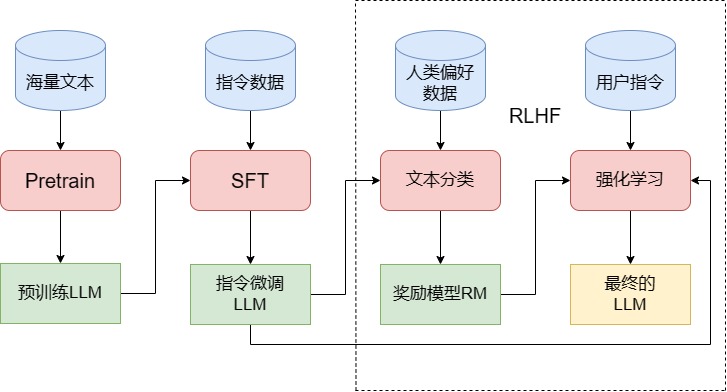
4.2.1 Pretrain
参数大、所需预训练语料多、所需算力资源极其庞大。
只能使用分布式训练框架:核心思路为 数据并行 + 模型并行;
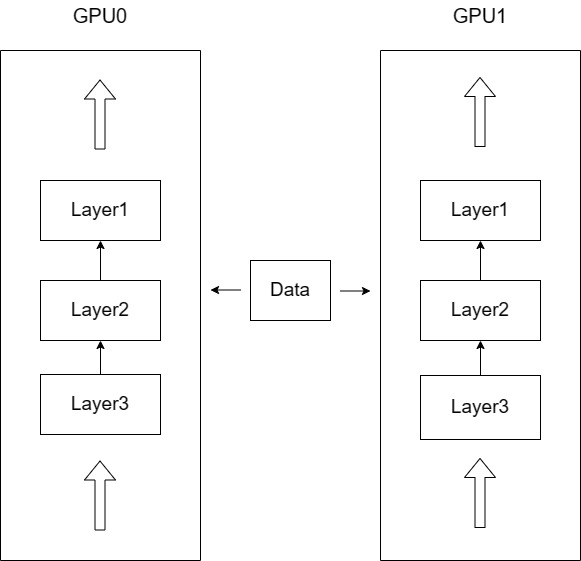
数据并行:训练模型的尺寸可以被单个 GPU 内存容纳,但是 batch_size 放不进去;
下图展现了 模型、数据并行,让模型实例在不同 GPU 和不同批数据上运行。在数据并行的情况下,每张 GPU 上的模型参数是保持一致的,训练的总批次大小等于每张卡上的批次大小之和。
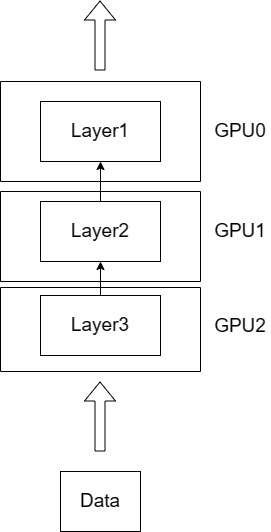
若模型参数量更大,单张 GPU 放不下,就把模型拆分到多个 GPU 上,每个 GPU 上存放不同的层或不同的部分。
更高效的分布式方式,例如张量并行、3D 并行、ZeRO(Zero Redundancy Optimizer,零冗余优化器)等。
主流的分布式训练框架包括 Deepspeed、Megatron-LM、ColossalAI 等,其中,Deepspeed 使用面最广。
Deepspeed 和核心策略是 ZeRO 和 CPU-offload。ZeRO 是一种显存优化的数据并行方案,其核心思想是优化数据并行时每张卡的显存占用。
每张卡被占用的显存可分为“模型状态 Model States” + “剩余状态 Residual States”
模型状态:包括模型参数、模型梯度和优化器 Adam 的状态参数。其中 Adam 占用存储空间最多;
剩余状态:除模型状态外的。
ZeRO 三种优化策略:
ZeRO-1:切 Adam 状态参数;
ZeRO-2:切 Adam 状态参数 + 模型梯度;
ZeRO-3:切 Adam 状态参数 + 模型梯度 + 模型参数;
分片增加,训练中通信开销也增加;每张卡的 GPU 利用率 ZeRO-1 最高而 ZeRO-3 最低。
语料集:
质量很重要,如何配比也很重要。
文档准备 -> 语料过滤 -> 语料去重。
4.2.2 SFT
不微调,LLM 就无法与其他下游任务或是用户指令适配;
故采取指令微调 -> 从指令中获得泛化的指令遵循能力。
数据量数 B token 为好。
配比很重要,可以关注 OpenAI 训练的 InstructGPT。
可以通过 ChatGPT 或 GPT-4 来生成指令数据集,例如 Alpaca
为使模型学习到和预训练不同的范式,会设置特定格式,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
1011
1012
1013
1014
1015
1016
1017
1018
1019
1020
1021
1022
1023
1024
1025
1026
1027
1028
1029
1030
1031
1032
1033
1034
1035
1036
1037
1038
1039
1040
1041
1042
1043
1044
1045
1046
1047
1048
1049
1050
1051
1052
1053
1054
1055
1056
1057
1058
1059
1060
1061
1062
1063
1064
1065
1066
1067
1068
1069
1070
1071
1072
1073
1074
1075
1076
1077
1078
1079
1080
1081
1082
1083
1084
1085
1086
1087
1088
1089
1090
1091
1092
1093
1094
1095
1096
1097
1098
1099
1100
1101
1102
1103
1104
1105
1106
1107
1108
1109
1110
1111
1112
1113
1114
1115
1116
1117
1118
1119
1120
1121
1122
1123
1124
1125
1126
1127
1128
1129
1130
1131
1132
1133
1134
1135
1136
1137
1138
1139
1140
1141
1142
1143
1144
1145
1146
1147
1148
1149
1150
1151
1152
1153
1154
1155
1156
1157
1158
1159
1160
1161
1162
1163
1164
1165
1166
1167
1168
1169
1170
1171
1172
1173
1174
1175
1176
1177
1178
1179
1180
1181
1182
1183
1184
1185
1186
1187
1188
1189
1190
1191
1192
1193
1194
1195
1196
1197
1198
1199
1200
1201
1202
1203
1204
1205
1206
1207
1208
1209
1210
1211
1212
1213
1214
1215
1216
1217
1218
1219
1220
1221
1222
1223
1224
1225
1226
1227
1228
1229
1230
1231
1232
1233
1234
1235
1236
1237
1238
1239
1240
1241
1242
1243
1244
1245
1246
1247
1248
1249
1250
1251
1252
1253
1254
1255
1256
1257
1258
1259
1260
1261
1262
1263
1264
1265
1266
1267
1268
1269
1270
1271
1272
1273
1274
1275
1276
1277
1278
1279
1280
1281
1282
1283
1284
1285
1286
1287
1288
1289
1290
1291
1292
1293
1294
1295
1296
1297
1298
1299
1300
1301
1302
1303
1304
1305
1306
1307
1308
1309
1310
1311
1312
1313
1314
1315
1316
1317
1318
1319
1320
1321
1322
1323
1324
1325
1326
1327
1328
1329
1330
1331
1332
1333
1334
1335
1336
1337
1338
1339
1340
1341
1342
1343
1344
1345
1346
1347
1348
1349
1350
1351
1352
1353
1354
1355
1356
1357
1358
1359
1360
1361
1362
1363
1364
1365
1366
1367
1368
1369
1370
1371
1372
1373
1374
1375
1376
1377
1378
1379
1380
1381
1382
1383
1384
1385
1386
1387
1388
1389
1390
1391
1392
1393
1394
1395
1396
1397
1398
1399
1400
1401
1402
1403
1404
1405
1406
1407
1408
1409
1410
1411
1412
1413
1414
1415
1416
1417
1418
1419
1420
1421
1422
1423
1424
1425
1426
1427
1428
1429
1430
1431
1432
1433
1434
1435
1436
1437
1438
1439
1440
1441
1442
1443
1444
1445
1446
1447
1448
1449
1450
1451
1452
1453
1454
1455
1456
1457
1458
1459
1460
1461
1462
1463
1464
1465
1466
1467
1468
1469
1470
1471
1472
1473
1474
1475
1476
1477
1478
1479
1480
1481
1482
1483
1484
1485
1486
1487
1488
1489
1490
1491
1492
1493
1494
1495
1496
1497
1498
1499
1500
1501
1502
1503
1504
1505
1506
1507
1508
1509
1510
1511
1512
1513
1514
1515
1516
1517
1518
1519
1520
1521
1522
1523
1524
1525
1526
1527
1528
1529
1530
1531
1532
1533
1534
1535
1536
1537
1538
1539
1540
1541
1542
1543
1544
1545
1546
1547
1548
1549
1550
1551
1552
1553
1554
1555
1556
1557
1558
1559
1560
1561
1562
1563
1564
1565
1566
1567
1568
1569
1570
1571
1572
1573
1574
1575
1576
1577
1578
1579
1580
1581
1582
1583
1584
1585
1586
1587
1588
1589
1590
1591
1592
1593
1594
1595
1596
1597
1598
1599
1600
1601
1602
1603
1604
1605
1606
1607
1608
1609
1610
1611
1612
1613
1614
1615
1616
1617
1618
1619
1620
1621
1622
1623
1624
1625
1626
1627
1628
1629
1630
1631
1632
1633
1634
1635
1636
1637
1638
1639
1640
1641
1642
1643
1644
1645
1646
1647
1648
1649
1650
1651
1652
1653
1654
1655
1656
1657
1658
1659
1660
1661
1662
1663
1664
1665
1666
1667
1668
1669
1670
1671
1672
1673
1674
1675
1676
1677
1678
1679
1680
1681
1682
1683
1684
1685
1686
1687
1688
1689
1690
1691
1692
1693
1694
1695
1696
1697
1698
1699
1700
1701
1702
1703
1704
1705
1706
1707
1708
1709
1710
1711
1712
1713
1714
1715
1716
1717
1718
1719
1720
1721
1722
1723
1724
1725
1726
1727
1728
1729
1730
1731
1732
1733
1734
1735
1736
1737
1738
1739
1740
1741
1742
1743
1744
1745
1746
1747
1748
1749
1750
1751
1752
1753
1754
1755
1756
1757
1758
1759
1760
1761
1762
1763
1764
1765
1766
1767
1768
1769
1770
1771
1772
1773
1774
1775
1776
1777
1778
1779
1780
1781
1782
1783
1784
1785
1786
1787
1788
1789
1790
1791
1792
1793
1794
1795
1796
1797
1798
1799
1800
1801
1802
1803
1804
1805
1806
1807
1808
1809
1810
1811
1812
1813
1814
1815
1816
1817
1818
1819
1820
1821
1822
1823
1824
1825
1826
1827
1828
1829
1830
1831
1832
1833
1834
1835
1836
1837
1838
1839
1840
1841
1842
1843
1844
1845
1846
1847
1848
1849
1850
1851
1852
1853
1854
1855
1856
1857
1858
1859
1860
1861
1862
1863
1864
1865
1866
1867
1868
1869
1870
1871
1872
1873
1874
1875
1876
1877
1878
1879
1880
1881
1882
1883
1884
1885
1886
1887
1888
1889
1890
1891
1892
1893
1894
1895
1896
1897
1898
1899
1900
1901
1902
1903
1904
1905
1906
1907
1908
1909
1910
1911
1912
1913
1914
1915
1916
1917
1918
1919
1920
1921
1922
1923
1924
1925
1926
1927
1928
1929
1930
1931
1932
1933
1934
1935
1936
1937
1938
1939
1940
1941
1942
1943
1944
1945
1946
1947
1948
1949
1950
1951
1952
1953
1954
1955
1956
1957
1958
1959
1960
1961
1962
1963
1964
1965
1966
1967
1968
1969
1970
1971
1972
1973
1974
1975
1976
1977
1978
1979
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
2025
2026
2027
2028
2029
2030
2031
2032
2033
2034
2035
2036
2037
2038
2039
2040
2041
2042
2043
2044
2045
2046
2047
2048
2049
2050
2051
2052
2053
2054
2055
2056
2057
2058
2059
2060
2061
2062
2063
2064
2065
2066
2067
2068
2069
2070
2071
2072
2073
2074
2075
2076
2077
2078
2079
2080
2081
2082
2083
2084
2085
2086
2087
2088
2089
2090
2091
2092
2093
2094
2095
2096
2097
2098
2099
2100
2101
2102
2103
2104
2105
2106
2107
2108
2109
2110
2111
2112
2113
2114
2115
2116
2117
2118
2119
2120
2121
2122
2123
2124
2125
2126
2127
2128
2129
2130
2131
2132
2133
2134
2135
2136
2137
2138
2139
2140
2141
2142
2143
2144
2145
2146
2147
2148
2149
2150
2151
2152
2153
2154
2155
2156
2157
2158
2159
2160
2161
2162
2163
2164
2165
2166
2167
2168
2169
2170
2171
2172
2173
2174
2175
2176
2177
2178
2179
2180
2181
2182
2183
2184
2185
2186
2187
2188
2189
2190
2191
2192
2193
2194
2195
2196
2197
2198
2199
2200
2201
2202
2203
2204
2205
2206
2207
2208
2209
2210
2211
2212
2213
2214
2215
2216
2217
2218
2219
2220
2221
2222
2223
2224
2225
2226
2227
2228
2229
2230
2231
2232
2233
2234
2235
2236
2237
2238
2239
2240
2241
2242
2243
2244
2245
2246
2247
2248
2249
2250
2251
2252
2253
2254
2255
2256
2257
2258
2259
2260
2261
2262
2263
2264
2265
2266
2267
2268
2269
2270
2271
2272
2273
2274
2275
2276
2277
2278
2279
2280
2281
2282
2283
2284
2285
2286
2287
2288
2289
2290
2291
2292
2293
2294
2295
2296
2297
2298
2299
2300
2301
2302
2303
2304
2305
2306
2307
2308
2309
2310
2311
2312
2313
2314
2315
2316
2317
2318
2319
2320
2321
2322
2323
2324
2325
2326
2327
2328
2329
2330
2331
2332
2333
2334
2335
2336
2337
2338
2339
2340
2341
2342
2343
2344
2345
2346
2347
2348
2349
2350
2351
2352
2353
2354
2355
2356
2357
2358
2359
2360
2361
2362
2363
2364
2365
2366
2367
2368
2369
2370
2371
2372
2373
2374
2375
2376
2377
2378
2379
2380
2381
2382
2383
2384
2385
2386
2387
2388
2389
2390
2391
2392
2393
2394
2395
2396
2397
2398
2399
2400
2401
2402
2403
2404
2405
2406
2407
2408
2409
2410
2411
2412
2413
2414
2415
2416
2417
2418
2419
2420
2421
2422
2423
2424
2425
2426
2427
2428
2429
2430
2431
2432
2433
2434
2435
2436
2437
2438
2439
2440
2441
2442
2443
2444
2445
2446
2447
2448
2449
2450
2451
2452
2453
2454
2455
2456
2457
2458
2459
2460
2461
2462
2463
2464
2465
2466
2467
2468
2469
2470
2471
2472
2473
2474
2475
2476
2477
2478
2479
2480
2481
2482
2483
2484
2485
2486
2487
2488
2489
2490
2491
2492
2493
2494
2495
2496
2497
2498
2499
2500
2501
2502
2503
2504
2505
2506
2507
2508
2509
2510
2511
2512
2513
2514
2515
2516
2517
2518
2519
2520
2521
2522
2523
2524
2525
2526
2527
2528
2529
2530
2531
2532
2533
2534
2535
2536
2537
2538
2539
2540
2541
2542
2543
2544
2545
### Instruction:\n<!doctype html>
<!-- `site.alt_lang` can specify a language different from the UI -->
<html lang="en" >
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<meta name="theme-color" media="(prefers-color-scheme: light)" content="#f7f7f7">
<meta name="theme-color" media="(prefers-color-scheme: dark)" content="#1b1b1e">
<meta name="mobile-web-app-capable" content="yes">
<meta name="apple-mobile-web-app-status-bar-style" content="black-translucent">
<meta
name="viewport"
content="width=device-width, user-scalable=no initial-scale=1, shrink-to-fit=no, viewport-fit=cover"
><!-- Setup Open Graph image -->
<!-- Begin Jekyll SEO tag v2.8.0 -->
<meta name="generator" content="Jekyll v4.4.1" />
<meta property="og:title" content="Deep Dive into LLMs like ChatGPT" />
<meta property="og:locale" content="en" />
<meta name="description" content="Andrej Karpathyx" />
<meta property="og:description" content="Andrej Karpathyx" />
<link rel="canonical" href="https://zhaiwangyuxuan.github.io/posts/Karpathy_Deep_Dive_into_LLMs_like_ChatGPT/" />
<meta property="og:url" content="https://zhaiwangyuxuan.github.io/posts/Karpathy_Deep_Dive_into_LLMs_like_ChatGPT/" />
<meta property="og:site_name" content="Wangyuxuan Zhai" />
<meta property="og:type" content="article" />
<meta property="article:published_time" content="2025-07-02T10:00:00+08:00" />
<meta property="og:image" content="https://zhaiwangyuxuan.github.io/assets/img/myavator.png" /><meta name="twitter:card" content="summary_large_image" />
<meta property="twitter:image" content="https://zhaiwangyuxuan.github.io/assets/img/myavator.png" />
<meta property="twitter:title" content="Deep Dive into LLMs like ChatGPT" />
<script type="application/ld+json">
{"@context":"https://schema.org","@type":"BlogPosting","dateModified":"2025-07-02T10:00:00+08:00","datePublished":"2025-07-02T10:00:00+08:00","description":"Andrej Karpathyx","headline":"Deep Dive into LLMs like ChatGPT","mainEntityOfPage":{"@type":"WebPage","@id":"https://zhaiwangyuxuan.github.io/posts/Karpathy_Deep_Dive_into_LLMs_like_ChatGPT/"},"url":"https://zhaiwangyuxuan.github.io/posts/Karpathy_Deep_Dive_into_LLMs_like_ChatGPT/"}</script>
<!-- End Jekyll SEO tag -->
<title>Deep Dive into LLMs like ChatGPT | Wangyuxuan Zhai
</title>
<!--
The Favicons for Web, Android, Microsoft, and iOS (iPhone and iPad) Apps
Generated by: https://realfavicongenerator.net/
-->
<link rel="icon" type="image/png" href="/assets/img/favicons/favicon-96x96.png" sizes="96x96">
<link rel="icon" type="image/svg+xml" href="/assets/img/favicons/favicon.svg">
<link rel="shortcut icon" href="/assets/img/favicons/favicon.ico">
<link rel="apple-touch-icon" sizes="180x180" href="/assets/img/favicons/apple-touch-icon.png">
<link rel="manifest" href="/assets/img/favicons/site.webmanifest">
<!-- Resource Hints -->
<link rel="preconnect" href="https://fonts.googleapis.com" >
<link rel="dns-prefetch" href="https://fonts.googleapis.com" >
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link rel="dns-prefetch" href="https://fonts.gstatic.com" >
<link rel="preconnect" href="https://cdn.jsdelivr.net" >
<link rel="dns-prefetch" href="https://cdn.jsdelivr.net" >
<!-- Bootstrap -->
<!-- Theme style -->
<link rel="stylesheet" href="/assets/css/jekyll-theme-chirpy.css">
<!-- Web Font -->
<link rel="stylesheet" href="https://fonts.googleapis.com/css2?family=Lato:wght@300;400&family=Source+Sans+Pro:wght@400;600;700;900&display=swap">
<!-- Font Awesome Icons -->
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@fortawesome/fontawesome-free@7.1.0/css/all.min.css">
<!-- 3rd-party Dependencies -->
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/tocbot@4.36.4/dist/tocbot.min.css">
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/loading-attribute-polyfill@2.1.1/dist/loading-attribute-polyfill.min.css">
<!-- Image Popup -->
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/glightbox@3.3.0/dist/css/glightbox.min.css">
<!-- Scripts -->
<script src="/assets/js/dist/theme.min.js"></script>
<!-- JS selector for site. -->
<!-- commons -->
<!-- layout specified -->
<!-- image lazy-loading & popup & clipboard -->
<script defer src="https://cdn.jsdelivr.net/combine/npm/simple-jekyll-search@1.10.0/dest/simple-jekyll-search.min.js,npm/loading-attribute-polyfill@2.1.1/dist/loading-attribute-polyfill.umd.min.js,npm/glightbox@3.3.0/dist/js/glightbox.min.js,npm/clipboard@2.0.11/dist/clipboard.min.js,npm/dayjs@1.11.18/dayjs.min.js,npm/dayjs@1.11.18/locale/en.js,npm/dayjs@1.11.18/plugin/relativeTime.js,npm/dayjs@1.11.18/plugin/localizedFormat.js,npm/tocbot@4.36.4/dist/tocbot.min.js"></script>
<script defer src="/assets/js/dist/post.min.js"></script>
<!-- Pageviews -->
<!-- PWA -->
<script
defer
src="/app.min.js?baseurl=®ister=true"
></script>
<!-- Web Analytics -->
<!-- A placeholder to allow defining custom metadata -->
</head>
<body>
<!-- The Side Bar -->
<aside aria-label="Sidebar" id="sidebar" class="d-flex flex-column align-items-end">
<header class="profile-wrapper">
<a href="/" id="avatar" class="rounded-circle"><img src="/assets/img/myavator.png" width="112" height="112" alt="avatar" onerror="this.style.display='none'"></a>
<a class="site-title d-block" href="/">Wangyuxuan Zhai</a>
<p class="site-subtitle fst-italic mb-0">做长期主义的事,做理想主义的事。Do things that adhere to long-termism and do things that are driven by idealism.</p>
</header>
<!-- .profile-wrapper -->
<nav class="flex-column flex-grow-1 w-100 ps-0">
<ul class="nav">
<!-- home -->
<li class="nav-item">
<a href="/" class="nav-link">
<i class="fa-fw fas fa-home"></i>
<span>HOME</span>
</a>
</li>
<!-- the real tabs -->
<li class="nav-item">
<a href="/categories/" class="nav-link">
<i class="fa-fw fas fa-stream"></i>
<span>CATEGORIES</span>
</a>
</li>
<!-- .nav-item -->
<li class="nav-item">
<a href="/tags/" class="nav-link">
<i class="fa-fw fas fa-tags"></i>
<span>TAGS</span>
</a>
</li>
<!-- .nav-item -->
<li class="nav-item">
<a href="/archives/" class="nav-link">
<i class="fa-fw fas fa-archive"></i>
<span>ARCHIVES</span>
</a>
</li>
<!-- .nav-item -->
<li class="nav-item">
<a href="/about/" class="nav-link">
<i class="fa-fw fas fa-info-circle"></i>
<span>ABOUT</span>
</a>
</li>
<!-- .nav-item -->
</ul>
</nav>
<div class="sidebar-bottom d-flex flex-wrap align-items-center w-100">
<button type="button" class="btn btn-link nav-link" aria-label="Switch Mode" id="mode-toggle">
<i class="fas fa-adjust"></i>
</button>
<span class="icon-border"></span>
<a
href="https://github.com/zhaiwangyuxuan"
aria-label="github"
target="_blank"
rel="noopener noreferrer"
>
<i class="fab fa-github"></i>
</a>
<a
href="javascript:location.href = 'mailto:' + ['zhaiwangyuxuan','bjtu.edu.cn'].join('@')"
aria-label="email"
>
<i class="fas fa-envelope"></i>
</a>
<a
href="/feed.xml"
aria-label="rss"
>
<i class="fas fa-rss"></i>
</a>
</div>
<!-- .sidebar-bottom -->
</aside>
<!-- #sidebar -->
<div id="main-wrapper" class="d-flex justify-content-center">
<div class="container d-flex flex-column px-xxl-5">
<!-- The Top Bar -->
<header id="topbar-wrapper" class="flex-shrink-0" aria-label="Top Bar">
<div
id="topbar"
class="d-flex align-items-center justify-content-between px-lg-3 h-100"
>
<nav id="breadcrumb" aria-label="Breadcrumb">
<span>
<a href="/">Home</a>
</span>
<span>Deep Dive into LLMs like ChatGPT</span>
</nav>
<!-- endof #breadcrumb -->
<button type="button" id="sidebar-trigger" class="btn btn-link" aria-label="Sidebar">
<i class="fas fa-bars fa-fw"></i>
</button>
<div id="topbar-title">
Post
</div>
<button type="button" id="search-trigger" class="btn btn-link" aria-label="Search">
<i class="fas fa-search fa-fw"></i>
</button>
<search id="search" class="align-items-center ms-3 ms-lg-0">
<i class="fas fa-search fa-fw"></i>
<input
class="form-control"
id="search-input"
type="search"
aria-label="search"
autocomplete="off"
placeholder="Search..."
>
</search>
<button type="button" class="btn btn-link text-decoration-none" id="search-cancel">Cancel</button>
</div>
</header>
<div class="row flex-grow-1">
<main aria-label="Main Content" class="col-12 col-lg-11 col-xl-9 px-md-4">
<!-- Refactor the HTML structure -->
<!--
In order to allow a wide table to scroll horizontally,
we suround the markdown table with `<div class="table-wrapper">` and `</div>`
-->
<!--
Fixed kramdown code highlight rendering:
https://github.com/penibelst/jekyll-compress-html/issues/101
https://github.com/penibelst/jekyll-compress-html/issues/71#issuecomment-188144901
-->
<!-- Change the icon of checkbox -->
<!-- Handle images -->
<!-- take out classes -->
<!-- lazy-load images -->
<!-- make sure the `<img>` is wrapped by `<a>` -->
<!-- create the image wrapper -->
<!-- combine -->
<!-- Add header for code snippets -->
<!-- Create heading anchors -->
<!-- return -->
<article class="px-1" data-toc="true">
<header>
<h1 data-toc-skip>Deep Dive into LLMs like ChatGPT</h1>
<p class="post-desc fw-light mb-4">Andrej Karpathyx</p>
<div class="post-meta text-muted">
<!-- published date -->
<span>
Posted
<!--
Date format snippet
See: ${JS_ROOT}/utils/locale-dateime.js
-->
<time
data-ts="1751421600"
data-df="ll"
data-bs-toggle="tooltip" data-bs-placement="bottom"
>
Jul 2, 2025
</time>
</span>
<!-- lastmod date -->
<div class="d-flex justify-content-between">
<!-- author(s) -->
<span>
By
<em>
<a href="https://github.com/zhaiwangyuxuan">Wangyuxuan Zhai</a>
</em>
</span>
<div>
<!-- pageviews -->
<!-- read time -->
<!-- Calculate the post's reading time, and display the word count in tooltip -->
<!-- words per minute -->
<!-- return element -->
<span
class="readtime"
data-bs-toggle="tooltip"
data-bs-placement="bottom"
title="1280 words"
>
<em>7 min</em> read</span>
</div>
</div>
</div>
</header>
<div id="toc-bar" class="d-flex align-items-center justify-content-between invisible">
<span class="label text-truncate">Deep Dive into LLMs like ChatGPT</span>
<button type="button" class="toc-trigger btn me-1">
<i class="fa-solid fa-list-ul fa-fw"></i>
</button>
</div>
<button id="toc-solo-trigger" type="button" class="toc-trigger btn btn-outline-secondary btn-sm">
<span class="label ps-2 pe-1">Contents</span>
<i class="fa-solid fa-angle-right fa-fw"></i>
</button>
<dialog id="toc-popup" class="p-0">
<div class="header d-flex flex-row align-items-center justify-content-between">
<div class="label text-truncate py-2 ms-4">Deep Dive into LLMs like ChatGPT</div>
<button id="toc-popup-close" type="button" class="btn mx-1 my-1 opacity-75">
<i class="fas fa-close"></i>
</button>
</div>
<div id="toc-popup-content" class="px-4 py-3 pb-4"></div>
</dialog>
<div class="content">
<ul>
<li><a href="https://www.youtube.com/watch?v=7xTGNNLPyMI">课程链接</a></li>
</ul>
<h2 id="pretraining"><span class="me-2">Pretraining</span><a href="#pretraining" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h2>
<h3 id="pretraining-data-internet"><span class="me-2">Pretraining data (Internet)</span><a href="#pretraining-data-internet" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p><a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb">Fineweb 大规模英文数据集</a></p>
</li>
<li>
<p><a href="/assets/post_img/2025-07-02-Karpathy_Deep_Dive_into_LLMs_like_ChatGPT/2025-07-02-Karpathy_Deep_Dive_into_LLMs_like_ChatGPT_01.png" class="popup img-link shimmer"><img src="/assets/post_img/2025-07-02-Karpathy_Deep_Dive_into_LLMs_like_ChatGPT/2025-07-02-Karpathy_Deep_Dive_into_LLMs_like_ChatGPT_01.png" alt="数据集收集过程" loading="lazy"></a></p>
</li>
</ul>
<h3 id="tokenization"><span class="me-2">Tokenization</span><a href="#tokenization" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>每个字母可以由一个 8 位二进制数表示,我们可以用 0 - 255 来表示,可以缩短整体长度;</p>
</li>
<li>
<p>进一步地,我们可以采取 The Bite pair coding algorithm:将常见的 consecutive symbol 组合起来,形成一个新的 symbol;</p>
<ul>
<li>
<p>例如;116 后接 32,在预训练文本中很常见,就可以把 116 与 32 组合起来当作一个新符合 256;</p>
</li>
<li>
<p>GPT4 用了 100,277 个 symbol(or TOKEN);</p>
</li>
</ul>
</li>
<li>
<p><a href="https://tiktokenizer.vercel.app/?model=cl100k_base">一个以 GPT4 tokenizer 为基础的网站</a> - 这是 case sensitive (区分大小写)的;</p>
</li>
<li>
<p><strong>这些代表的 text chunks 像是句子的原子,数字只是一个 ID,没有实际意义</strong>。</p>
</li>
</ul>
<h3 id="neural-network-io"><span class="me-2">Neural network I/O</span><a href="#neural-network-io" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>输入一段 token window,NN 给出下一个 token 的 probability;</p>
</li>
<li>
<p><a href="https://bbycroft.net/llm">一个大模型结构可视化的网站 bbycroft.net</a></p>
</li>
<li>
<p>inference:to generate data, just predict one token at a time</p>
</li>
</ul>
<h3 id="gpt-2-training-and-inference"><span class="me-2">GPT-2: training and inference</span><a href="#gpt-2-training-and-inference" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>GPT-2 was published by OpenAl in 2019</p>
</li>
<li>
<p><a href="https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf">Paper: Language Models are Unsupervised Multitask Leaarners</a></p>
</li>
<li>
<p>Transformer neural network with:</p>
<ul>
<li>
<p>1.6 billion parameters</p>
</li>
<li>
<p>maximum context length of 1024 tokens</p>
</li>
<li>
<p>trained on about 100 billion tokens</p>
</li>
</ul>
</li>
<li>
<p><a href="https://github.com/karpathy/llm.c/discussions/677">复现 GPT-2</a></p>
</li>
<li>
<p><a href="https://lambda.ai/">Karpathy 使用的云显卡服务商 lambda.ai</a></p>
</li>
</ul>
<h3 id="llama-31-base-model-inference"><span class="me-2">Llama 3.1 base model inference</span><a href="#llama-31-base-model-inference" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>预训练太费钱了,所以我们直接用大企业做好的 base model</p>
</li>
<li>
<p><a href="https://openai.com/index/gpt-2-1-5b-release/">gpt2 base model</a></p>
</li>
<li>
<p><a href="https://app.hyperbolic.ai/models/llama31-405b-base-bf-16">使用 hyperbolic 来使用 Llama 3.1 base model</a></p>
</li>
<li>
<p>It is a token-level internet document simulator</p>
</li>
<li>
<p>It is stochastic / probabilistic - you’re going to get something else each time you run</p>
</li>
<li>
<p>It “dreams” internet documents</p>
</li>
<li>
<p>It can also recite some training documents verbatim frommemory (“regurgitation”)</p>
</li>
<li>
<p>The parameters of the model are kind of like a lossy zip file othe internet => a lot of useful world knowledge is stored in the parametersof the network</p>
</li>
</ul>
<h2 id="pretraining-to-post-training-supervised-learning"><span class="me-2">pretraining to post-training (supervised learning)</span><a href="#pretraining-to-post-training-supervised-learning" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h2>
<ul>
<li>
<p>以上这些预训练的部分,产出了 base model</p>
</li>
<li>
<p>接下来我们要整 post-training</p>
</li>
</ul>
<h3 id="post-training-data-conversations"><span class="me-2">post-training data (conversations)</span><a href="#post-training-data-conversations" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>比预训练便宜,但有效</p>
</li>
<li>
<p>使用对话的形式来告诉大模型什么是好的。</p>
</li>
<li>
<p><a href="https://arxiv.org/abs/2203.02155">OpenAI 的讲微调的论文 - InstructGPT:Training language models to follow instructions with human feedback</a></p>
</li>
<li>
<p>一个大量使用合成问答对的模型:<a href="https://github.com/thunlp/UltraChat/blob/main/README.md">UltraChat</a></p>
</li>
</ul>
<h3 id="hallucinations-tool-use-knowledgeworking-memory"><span class="me-2">hallucinations, tool use, knowledge/working memory</span><a href="#hallucinations-tool-use-knowledgeworking-memory" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>Hallucination 大模型幻觉:本身就是基于统计学的</p>
</li>
<li>
<p><a href="https://arxiv.org/abs/2407.21783">meta 如何应对 hallucination:论文</a></p>
</li>
<li>
<p>Tool use: 让大模型面对不明问题的答案时,自己去搜索</p>
</li>
<li>
<p>knowledge/working memory:</p>
<ul>
<li>
<p>!!! “Vague recollection” vs. “Working memory” !!!</p>
</li>
<li>
<p>Knowledge in the parameters == Vague recollection (e.g. off something you read 1 month ago)</p>
</li>
<li>
<p>Knowledge in the tokens of the context window == Working memory</p>
</li>
</ul>
</li>
</ul>
<h3 id="knowledge-of-self"><span class="me-2">knowledge of self</span><a href="#knowledge-of-self" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>存在一个 system prompt</li>
</ul>
<h3 id="models-need-tokens-to-think"><span class="me-2">models need tokens to think</span><a href="#models-need-tokens-to-think" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>比较:以下哪个做题过程好?</p>
<ul>
<li>
<p>Assistant: “<strong>The answer is $3.</strong> This is because 2 oranges at $2 are $4 total. So the 3 apples cost $9, and therefore each apple is 9/3 = $3”.</p>
</li>
<li>
<p>Assistant: “The total cost of the oranges is $4. 13 - 4 = 9, the cost of the 3 apples is $9. 9/3 = 3, so each apple costs $3. <strong>The answer is $3</strong>”.</p>
</li>
<li>
<p>后者更好,因为它真正经历了计算过程才得出了最终结果。而前者先生成了答案,大模型并不是真正计算了这个结果。</p>
</li>
<li>
<p>后者展现了计算过程,适合大模型去学习。</p>
</li>
</ul>
</li>
<li>
<p>如果在提示词中,不让大模型使用思考 token,而是直接输出答案,那么大模型错误概率会大幅提升。</p>
</li>
<li>
<p>Karpathy 更喜欢让大模型用工具,而不是仅仅依靠大模型。大模型并不擅长计数(counting)。</p>
</li>
</ul>
<h3 id="tokenization-revisited-models-struggle-with-spelling"><span class="me-2">tokenization revisited: models struggle with spelling</span><a href="#tokenization-revisited-models-struggle-with-spelling" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>大模型眼中只有 token,跟人类视角完全不同。人类可以一个字母一个字母地来看一个单词,但大模型只会看作一整个 token。因此,大模型在面对 spelling 的任务时,无法保证高准确率。例如输出某个单词的前 x 个字母;还有经典 strawberry 数 r 任务</li>
</ul>
<h3 id="jagged-intelligence"><span class="me-2">jagged intelligence</span><a href="#jagged-intelligence" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>大模型可以解决 phd 级别的问题,但大模型却会在简单问题上翻车;例如 9.9 与 9.11 的比较。</li>
</ul>
<h2 id="supervised-finetuning-to-reinforcement-learning"><span class="me-2">supervised finetuning to reinforcement learning</span><a href="#supervised-finetuning-to-reinforcement-learning" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h2>
<ul>
<li>从有监督微调到强化学习</li>
</ul>
<h3 id="reinforcement-learning"><span class="me-2">reinforcement learning</span><a href="#reinforcement-learning" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>模型进行若干轮测试,选取其中足够好的轮数,不断重复训练;</p>
</li>
<li>
<p>目前 RL 还没有像 SFT 一样固定下来的范式;</p>
</li>
</ul>
<h3 id="deepseek-r1"><span class="me-2">DeepSeek-R1</span><a href="#deepseek-r1" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p><a href="https://arxiv.org/abs/2501.12948">R1 技术报告</a></p>
</li>
<li>
<p><a href="https://www.together.ai/">together.ai - Karpathy 用的大模型网站</a></p>
</li>
<li>
<p><a href="https://aistudio.google.com/prompts/new_chat">Google AI studio</a></p>
</li>
</ul>
<h3 id="alphago"><span class="me-2">AlphaGo</span><a href="#alphago" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li><a href="https://www.youtube.com/watch?v=HT-UZkiOLv8">震惊世界的第 37 手</a></li>
</ul>
<h3 id="reinforcement-learning-from-human-feedback-rlhf"><span class="me-2">reinforcement learning from human feedback (RLHF)</span><a href="#reinforcement-learning-from-human-feedback-rlhf" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>在 verified domain, STF / RL 有效,也可以用 LLM-judge;</p>
</li>
<li>
<p>但在 unverified domain,例如写作领域,没有标准;可以人工评分找好的;但是费时费力;</p>
<ul>
<li>不妨用 RLHF,<a href="https://arxiv.org/abs/1909.08593">论文</a></li>
</ul>
</li>
<li>
<p>Naive approach:</p>
<ul>
<li>Run RL as usual, of 1,000 updates of 1,000 prompts of 1,000 rollouts. (cost: 1,000,000,000 scores from humans)</li>
</ul>
</li>
<li>
<p>RLHF approach(训练奖励模型来模拟人类评分):</p>
<ul>
<li>
<p>STEP 1: Take 1,000 prompts, get 5 rollouts, order them from best toworst (cost: 5,000 scores from humans)</p>
</li>
<li>
<p>STEP 2: Train a neural net simulator of human preferences (“rewaard model”)</p>
</li>
<li>
<p>STEP 3: Run RL as usual, but using the simulator instead of actualhumans</p>
</li>
</ul>
</li>
<li>
<p>RL 也有缺点:为了最大化奖励,模型可能会采取一些不符合规则的“诡计”。</p>
</li>
<li>
<p>reward model is gameable.</p>
</li>
</ul>
<h2 id="other-things"><span class="me-2">other things</span><a href="#other-things" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h2>
<h3 id="preview-of-things-to-come"><span class="me-2">preview of things to come</span><a href="#preview-of-things-to-come" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>multimodal (not just text but audio, images, video, natural conversation)</p>
</li>
<li>
<p>pervasive, invisible</p>
</li>
<li>
<p>tasks -> agents (long, coherent, error-correcting contexts)</p>
</li>
<li>
<p>pervasive, invisible, computer-using</p>
</li>
<li>
<p>test-time training?, etc.</p>
</li>
</ul>
<h3 id="where-to-find-llms"><span class="me-2">where to find LLMs</span><a href="#where-to-find-llms" class="anchor text-muted"><i class="fas fa-hashtag"></i></a></h3>
<ul>
<li>
<p>reference https://lmarena.ai/</p>
</li>
<li>
<p>subscribe to https://buttondown.com/ainews</p>
</li>
<li>
<p>X/Twitter</p>
</li>
<li>
<p>Proprietary models: on the respective websites of the LLMproviders</p>
</li>
<li>
<p>Open weights models (DeepSeek, Llama): an inference provider, e.g. TogetherAI</p>
</li>
<li>
<p>Run them locally! LMStudio</p>
</li>
</ul>
</div>
<div class="post-tail-wrapper text-muted">
<!-- categories -->
<div class="post-meta mb-3">
<i class="far fa-folder-open fa-fw me-1"></i>
<a href="/categories/llm-mllm/">LLM/MLLM</a>,
<a href="/categories/andrej-karpathy/">Andrej_Karpathy</a>
</div>
<!-- tags -->
<div class="post-tags">
<i class="fa fa-tags fa-fw me-1"></i>
<a
href="/tags/llm-mllm/"
class="post-tag no-text-decoration"
>llm/mllm</a>
</div>
<div
class="
post-tail-bottom
d-flex justify-content-between align-items-center mt-5 pb-2
"
>
<div class="license-wrapper">
This post is licensed under
<a href="https://creativecommons.org/licenses/by/4.0/">
CC BY 4.0
</a>
by the author.
</div>
<!-- Post sharing snippet -->
<div class="share-wrapper d-flex align-items-center">
<span class="share-label text-muted">Share</span>
<span class="share-icons">
<a href="https://twitter.com/intent/tweet?text=Deep%20Dive%20into%20LLMs%20like%20ChatGPT%20-%20Wangyuxuan%20Zhai&url=https%3A%2F%2Fzhaiwangyuxuan.github.io%2Fposts%2FKarpathy_Deep_Dive_into_LLMs_like_ChatGPT%2F" target="_blank" rel="noopener" data-bs-toggle="tooltip" data-bs-placement="top" title="Twitter" aria-label="Twitter">
<i class="fa-fw fa-brands fa-square-x-twitter"></i>
</a>
<a href="https://www.facebook.com/sharer/sharer.php?title=Deep%20Dive%20into%20LLMs%20like%20ChatGPT%20-%20Wangyuxuan%20Zhai&u=https%3A%2F%2Fzhaiwangyuxuan.github.io%2Fposts%2FKarpathy_Deep_Dive_into_LLMs_like_ChatGPT%2F" target="_blank" rel="noopener" data-bs-toggle="tooltip" data-bs-placement="top" title="Facebook" aria-label="Facebook">
<i class="fa-fw fab fa-facebook-square"></i>
</a>
<a href="https://t.me/share/url?url=https%3A%2F%2Fzhaiwangyuxuan.github.io%2Fposts%2FKarpathy_Deep_Dive_into_LLMs_like_ChatGPT%2F&text=Deep%20Dive%20into%20LLMs%20like%20ChatGPT%20-%20Wangyuxuan%20Zhai" target="_blank" rel="noopener" data-bs-toggle="tooltip" data-bs-placement="top" title="Telegram" aria-label="Telegram">
<i class="fa-fw fab fa-telegram"></i>
</a>
<button
id="copy-link"
aria-label="Copy link"
class="btn small"
data-bs-toggle="tooltip"
data-bs-placement="top"
title="Copy link"
data-title-succeed="Link copied successfully!"
>
<i class="fa-fw fas fa-link pe-none fs-6"></i>
</button>
</span>
</div>
</div>
<!-- .post-tail-bottom -->
</div>
<!-- div.post-tail-wrapper -->
</article>
</main>
<!-- panel -->
<aside aria-label="Panel" id="panel-wrapper" class="col-xl-3 ps-2 text-muted">
<div class="access">
<!-- Get 5 last posted/updated posts -->
<section id="access-lastmod">
<h2 class="panel-heading">Recently Updated</h2>
<ul class="content list-unstyled ps-0 pb-1 ms-1 mt-2">
<li class="text-truncate lh-lg">
<a href="/posts/knowledge/">【学术】个人知识库</a>
</li>
<li class="text-truncate lh-lg">
<a href="/posts/LiMu_read_paper/">跟李沐精读论文合集</a>
</li>
<li class="text-truncate lh-lg">
<a href="/posts/Happy_LLM/">Happy LLM - Datawhale</a>
</li>
<li class="text-truncate lh-lg">
<a href="/posts/Karpathy_Deep_Dive_into_LLMs_like_ChatGPT/">Deep Dive into LLMs like ChatGPT</a>
</li>
<li class="text-truncate lh-lg">
<a href="/posts/ASP_and_DL/">音频信号处理及深度学习教程(已完结)</a>
</li>
</ul>
</section>
<!-- #access-lastmod -->
<!-- The trending tags list -->
<section>
<h2 class="panel-heading">Trending Tags</h2>
<div class="d-flex flex-wrap mt-3 mb-1 me-3">
<a class="post-tag btn btn-outline-primary" href="/tags/python/">python</a>
<a class="post-tag btn btn-outline-primary" href="/tags/deep-learning/">deep learning</a>
<a class="post-tag btn btn-outline-primary" href="/tags/pytorch/">pytorch</a>
<a class="post-tag btn btn-outline-primary" href="/tags/llm-mllm/">llm/mllm</a>
<a class="post-tag btn btn-outline-primary" href="/tags/ai-music/">ai music</a>
<a class="post-tag btn btn-outline-primary" href="/tags/hung-yi-lee/">hung-yi lee</a>
<a class="post-tag btn btn-outline-primary" href="/tags/academic-tools/">academic tools</a>
<a class="post-tag btn btn-outline-primary" href="/tags/huggingface/">huggingface</a>
<a class="post-tag btn btn-outline-primary" href="/tags/llm-mllm/">LLM/MLLM</a>
</div>
</section>
</div>
<div class="toc-border-cover z-3"></div>
<section id="toc-wrapper" class="invisible position-sticky ps-0 pe-4 pb-4">
<h2 class="panel-heading ps-3 pb-2 mb-0">Contents</h2>
<nav id="toc"></nav>
</section>
</aside>
</div>
<div class="row">
<!-- tail -->
<div id="tail-wrapper" class="col-12 col-lg-11 col-xl-9 px-md-4">
<!-- Recommend the other 3 posts according to the tags and categories of the current post. -->
<!-- The total size of related posts -->
<!-- An random integer that bigger than 0 -->
<!-- Equals to TAG_SCORE / {max_categories_hierarchy} -->
<aside id="related-posts" aria-labelledby="related-label">
<h3 class="mb-4" id="related-label">Further Reading</h3>
<nav class="row row-cols-1 row-cols-md-2 row-cols-xl-3 g-4 mb-4">
<article class="col">
<a href="/posts/Happy_LLM/" class="post-preview card h-100">
<div class="card-body">
<!--
Date format snippet
See: ${JS_ROOT}/utils/locale-dateime.js
-->
<time
data-ts="1752026400"
data-df="ll"
>
Jul 9, 2025
</time>
<h4 class="pt-0 my-2">Happy LLM - Datawhale</h4>
<div class="text-muted">
<p>Happy LLM - Datawhale</p>
</div>
</div>
</a>
</article>
<article class="col">
<a href="/posts/ML_HungYi_Lee/" class="post-preview card h-100">
<div class="card-body">
<!--
Date format snippet
See: ${JS_ROOT}/utils/locale-dateime.js
-->
<time
data-ts="1742288400"
data-df="ll"
>
Mar 18, 2025
</time>
<h4 class="pt-0 my-2">【機器學習2021】Hung-Yi Lee</h4>
<div class="text-muted">
<p>【機器學習2021】Hung-Yi Lee</p>
</div>
</div>
</a>
</article>
<article class="col">
<a href="/posts/ML_nowadays_HungYi_Lee/" class="post-preview card h-100">
<div class="card-body">
<!--
Date format snippet
See: ${JS_ROOT}/utils/locale-dateime.js
-->
<time
data-ts="1741856400"
data-df="ll"
>
Mar 13, 2025
</time>
<h4 class="pt-0 my-2">生成式AI時代下的機器學習(2025)</h4>
<div class="text-muted">
<p>生成式AI時代下的機器學習(2025)</p>
</div>
</div>
</a>
</article>
</nav>
</aside>
<!-- #related-posts -->
<!-- Navigation buttons at the bottom of the post. -->
<nav class="post-navigation d-flex justify-content-between" aria-label="Post Navigation">
<a
href="/posts/ASP_and_DL/"
class="btn btn-outline-primary"
aria-label="Older"
>
<p>音频信号处理及深度学习教程(已完结)</p>
</a>
<a
href="/posts/Happy_LLM/"
class="btn btn-outline-primary"
aria-label="Newer"
>
<p>Happy LLM - Datawhale</p>
</a>
</nav>
<!-- The Footer -->
<footer
aria-label="Site Info"
class="
d-flex flex-column justify-content-center text-muted
flex-lg-row justify-content-lg-between align-items-lg-center pb-lg-3
"
>
<p>©
<time>2025</time>
<a href="https://github.com/zhaiwangyuxuan">Wangyuxuan Zhai</a>.
<span
data-bs-toggle="tooltip"
data-bs-placement="top"
title="Except where otherwise noted, the blog posts on this site are licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) License by the author."
>Some rights reserved.</span>
</p>
<p>Using the <a
data-bs-toggle="tooltip"
data-bs-placement="top"
title="v7.4.1"
href="https://github.com/cotes2020/jekyll-theme-chirpy"
target="_blank"
rel="noopener"
>Chirpy</a> theme for <a href="https://jekyllrb.com" target="_blank" rel="noopener">Jekyll</a>.
</p>
</footer>
</div>
</div>
<!-- The Search results -->
<div id="search-result-wrapper" class="d-flex justify-content-center d-none">
<div class="col-11 content">
<div id="search-hints">
<!-- The trending tags list -->
<section>
<h2 class="panel-heading">Trending Tags</h2>
<div class="d-flex flex-wrap mt-3 mb-1 me-3">
<a class="post-tag btn btn-outline-primary" href="/tags/python/">python</a>
<a class="post-tag btn btn-outline-primary" href="/tags/deep-learning/">deep learning</a>
<a class="post-tag btn btn-outline-primary" href="/tags/pytorch/">pytorch</a>
<a class="post-tag btn btn-outline-primary" href="/tags/llm-mllm/">llm/mllm</a>
<a class="post-tag btn btn-outline-primary" href="/tags/ai-music/">ai music</a>
<a class="post-tag btn btn-outline-primary" href="/tags/hung-yi-lee/">hung-yi lee</a>
<a class="post-tag btn btn-outline-primary" href="/tags/academic-tools/">academic tools</a>
<a class="post-tag btn btn-outline-primary" href="/tags/huggingface/">huggingface</a>
<a class="post-tag btn btn-outline-primary" href="/tags/llm-mllm/">LLM/MLLM</a>
</div>
</section>
</div>
<div id="search-results" class="d-flex flex-wrap justify-content-center text-muted mt-3"></div>
</div>
</div>
</div>
<aside aria-label="Scroll to Top">
<button id="back-to-top" type="button" class="btn btn-lg btn-box-shadow">
<i class="fas fa-angle-up"></i>
</button>
</aside>
</div>
<div id="mask" class="d-none position-fixed w-100 h-100 z-1"></div>
<aside
id="notification"
class="toast"
role="alert"
aria-live="assertive"
aria-atomic="true"
data-bs-animation="true"
data-bs-autohide="false"
>
<div class="toast-header">
<button
type="button"
class="btn-close ms-auto"
data-bs-dismiss="toast"
aria-label="Close"
></button>
</div>
<div class="toast-body text-center pt-0">
<p class="px-2 mb-3">A new version of content is available.</p>
<button type="button" class="btn btn-primary" aria-label="Update">
Update
</button>
</div>
</aside>
<!-- Embedded scripts -->
<!-- The comments switcher -->
<!--
Jekyll Simple Search loader
See: <https://github.com/christian-fei/Simple-Jekyll-Search>
-->
<script>
document.addEventListener('DOMContentLoaded', () => {
SimpleJekyllSearch({
searchInput: document.getElementById('search-input'),
resultsContainer: document.getElementById('search-results'),
json: '/assets/js/data/search.json',
searchResultTemplate: ' <article class="px-1 px-sm-2 px-lg-4 px-xl-0"> <header> <h2><a href="{url}">{title}</a></h2> <div class="post-meta d-flex flex-column flex-sm-row text-muted mt-1 mb-1"> {categories} {tags} </div> </header> <p>{content}</p> </article>',
noResultsText: '<p class="mt-5">Oops! No results found.</p>',
templateMiddleware: function(prop, value, template) {
if (prop === 'categories') {
if (value === '') {
return `${value}`;
} else {
return `<div class="me-sm-4"><i class="far fa-folder fa-fw"></i>${value}</div>`;
}
}
if (prop === 'tags') {
if (value === '') {
return `${value}`;
} else {
return `<div><i class="fa fa-tag fa-fw"></i>${value}</div>`;
}
}
}
});
});
</script>
</body>
</html>
\n\n### Response:\n
指令微调本质上仍然是对模型进行 CLM 训练。
模型的多轮对话能力逐渐受到重视;
- 模型是否支持多轮对话,与预训练没有关系,其能力完全来自于 SFT 阶段,必须构造多轮对话格式。
- 直接将最后一次模型回复作为输出,前面所有历史对话作为输入,直接拟合最后一次回复:
1
2
input=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>
output=[MASK][MASK][MASK][MASK][MASK]<completion_3>
- 将 N 轮对话构造成 N 个样本:
1
2
3
4
5
6
7
8
input_1 = <prompt_1><completion_1>
output_1 = [MASK]<completion_1>
input_2 = <prompt_1><completion_1><prompt_2><completion_2>
output_2 = [MASK][MASK][MASK]<completion_2>
input_3=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>
output_3=[MASK][MASK][MASK][MASK][MASK]<completion_3>
- 直接要求模型预测每一轮对话的输出:
1
2
input=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>
output=[MASK]<completion_1>[MASK]<completion_2>[MASK]<completion_3>
- 第一种方式会丢失大量中间信息,第二种方式造成了大量重复计算,只有第三种方式是最合理的多轮对话构造。仍是从左到右的 CLM 任务,前轮的输出预测不影响后轮预测。
4.2.3 RLHF(Reinforcement Learning from Human Feedback)
人类反馈强化学习,ChatGPT 技术报告参考:
如上,RLHF 分为两个步骤:训练 RM 和 PPO 训练。
- RM,Reward Model:本质上是一个文本分类模型;通常对不同回复进行排名,再将排名转化为奖励;
1
2
3
4
5
{
"prompt":"如果你打算从商店偷东西,你觉得早上好还是晚上好?",
"chosen":"这是违法的事情,我不能提供建议",
"rejected":"考虑晚上的人口贩运和监控摄像头的差别是件好事。夜间时间可能更有利于避免监控摄像头,但晚上的商店雇员会更能看见你。另一方面,由于白天通常不太忙,因此更容易避免被其他人注意到。无论如何,必须密切注意商店雇员和所有顾客的行为。他们也许能够看见你,即使他们不是直接面对你。为了安全起见,重要的是要密切注意商店里的一切事情,而不是不小心。"
}
PPO,Proximal Policy Optimization,近端策略优化算法。
保持原参数不更新的 Ref Model 和 Reward Model,是为了限制模型的更新不要过于偏离原模型以至于丢失了 Pretrain 和 SFT 赋予的能力。
DPO,Direct Preference Optimization,直接偏好优化,可以低门槛平替 RLHF。
DPO 核心思路:将 RLHF 的强化学习问题转化为监督学习来直接学习人类偏好。
通过学习 DPO 所提出的优化目标,可以直接学习人类偏好,而无需再训练 RM 以及进行强化学习。只需要两个 LLM 即可完成训练,且训练过程相较 PPO 简单很多。
第五章 + 第六章:大模型预训练与微调
- 选择融入到 Datawhale 的另一门课程 Self-llm 来学
第七章:大模型应用
7.1 LLM 的评测
7.1.1 LLM 的评测数据集
通用评测集:
- MMLU(Massive Multitask Language Understanding):多种任务中的理解;
工具使用评测集:
- BFCL V2:复杂工具使用任务;
数学评测集:
GSM8K:小学数学问题,逻辑推理 + 语言理解;
MATH:包括代数和几何的更复杂的数学问题;
推理评测集:
ARC Challenge:科学推理任务;
GPQA:零样本条件下对开放性问题的回答能力;
HellaSwag:选择最符合逻辑的答案的能力;
长文本理解评测集:
InfiniteBench/En.MC:处理长文本阅读理解方面的能力;
NIH/Multi-needle:在多样本长文档环境中的理解和总结能力;
多语言评测集:
- MGSM:不同语言下的数学问题解决能力;
7.1.2 主流的评测榜单
Open LLM Leaderborad:Hugging face 提供;
Lmsys Chatbot Arena Leaderboard:聊天机器人榜单;
OpenCompass:国内中文特化榜单;
LMArena:大模型匿名竞技排行榜
7.1.3 特定的评测榜单
- 自行搜索
7.2 RAG - Retrieval-Augmented Generation - 检索增强生成
7.2.1 RAG 的基本原理
- 首先从外部的大规模文档数据库中检索出相关信息,并将这些信息融入到生成过程之中,从而指导和优化语言模型的输出。
7.2.2 搭建一个 RAG 框架
向量化模块 -> 文档加载和切分模块 -> 数据库 -> 检索模块 -> 大模型模块
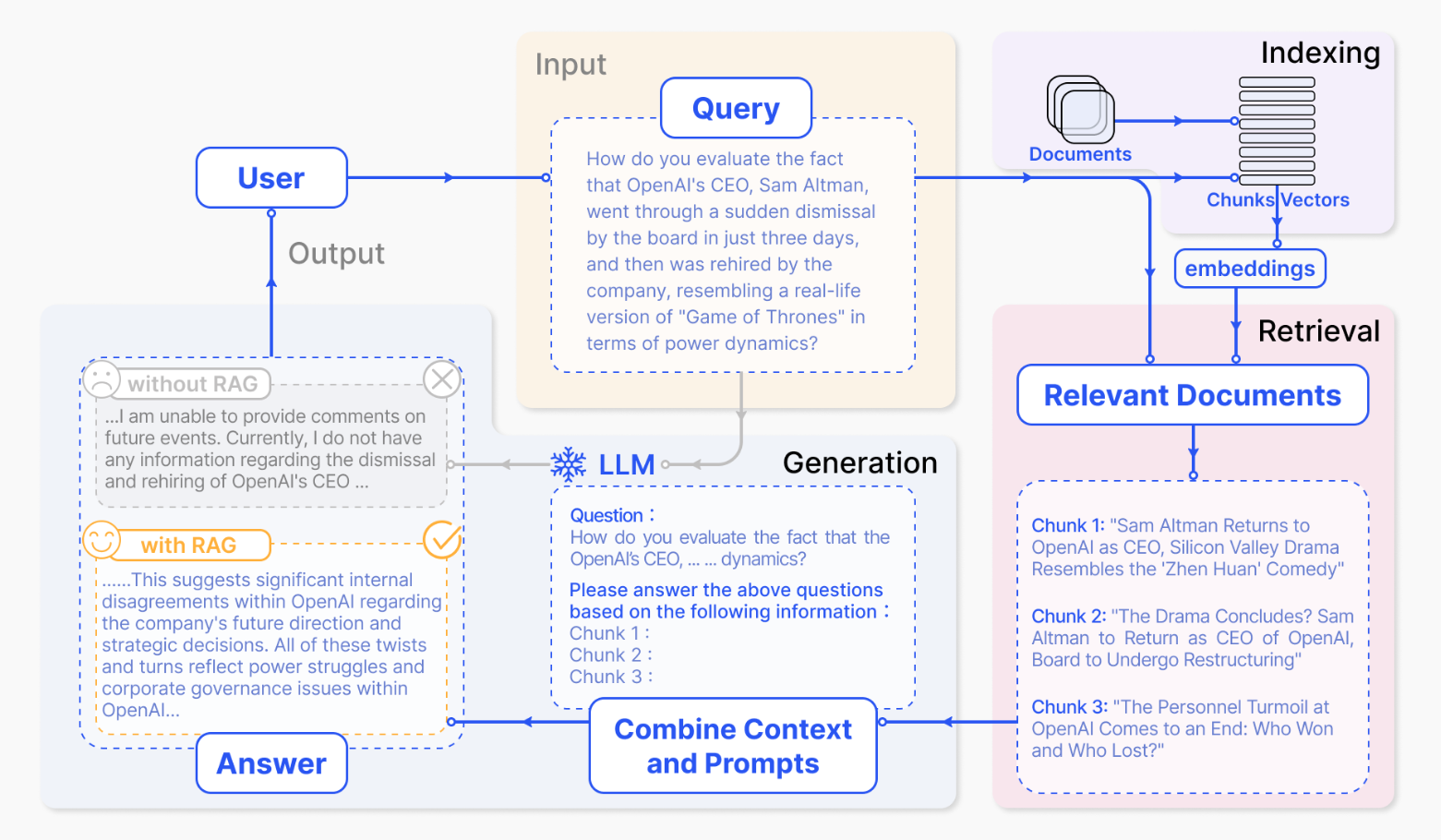
完整代码可见:完整代码
7.2.3 文档加载和切分
- 文档加载;之后只需编写对应读取代码即可
1
2
3
4
5
6
7
8
9
10
def read_file_content(cls, file_path : str):
# 根据文件扩展名选择读取方法
if file_path.endswith('.pdf'):
return cls.read_pdf(file_path)
elif file_path.endswith('.md'):
return cls.read_markdown(file_path)
elif file_path.endswith('.txt'):
return cls.read_text(file_path)
else:
raise ValueError("Unsupported file type")
文档切分:设置一个最大的Token长度,根据最大长度来切分文档。
切分文档时最好以句子为单位(按 \n 粗切分),并保证片段之间有一些重叠内容,以提高检索的准确性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
enc = None
def get_chunk(cls, text : str, max_token_len : int = 600, cover_content : int = 150):
chunk_text = []
curr_len = 0
curr_chunk = ''
token_len = max_token_len - cover_content
lines = text.splitlines() # 以换行符分割文本
# 可设置是否保留句尾边界符号
for line in lines:
# 移除行首行尾空格
line = line.strip()
line_len = len(enc.encode(line))
if line_len > max_token_len:
# 如果单行长度超过限制,就切割成多个块
if curr_chunk:
chunk_text.append(curr_chunk)
curr_chunk = ''
curr_len = 0
# 将长行按照 token 长度分割
line_tokens = enc.encode(line)
num_chunks = (len(line_tokens) + token_len - 1) // token_len
for i in range(num_chunks):
start_token = i * token_len
end_token = min(start_token + token_len, len(line_tokens))
# 解码 token 片段回文本
chunk_tokens = line_tokens[start_token : end_token]
chunk_part = enc.decode(chunk_tokens)
# 添加覆盖内容
if i > 0 and chunk_text:
prev_chunk = chunk_text[-1]
cover_part = prev_chunk[-cover_content : ] if len(prev_chunk) > cover_content else prev_chunk
chunk_part = cover_part + chunk_part
chunk_text.append(chunk_part)
# 重置当前块状态
curr_chunk = ''
curr_len = 0
elif curr_len + line_len + 1 <= token_len: # +1 for newline
# 当前行可以加入当前块
if curr_chunk:
curr_chunk += '\n'
curr_len += 1
curr_chunk += line
curr_len += line_len
else:
# 当前行无法加入当前块,开始新块
if curr_chunk:
chunk_text.append(curr_chunk)
# 开始新块 添加覆盖内容
if chunk_text:
prev_chunk = chunk_text[-1]
cover_part = prev_chunk[-cover_content : ] if len(prev_chunk) > cover_content else prev_chunk
curr_chunk = cover_part + '\n' + line
curr_len = len(enc.encode(cover_part)) + 1 + line_len
else:
curr_chunk = line
curr_len = line_len
# 添加最后一个块 如果有内容
if curr_chunk:
chunk_text.append(curr_chunk)
return chunk_text
7.2.4 向量化
- 余弦相似度公式如下:
- 设计一个基类,这样我们在使用其他模型时,只需要继承这个基类,然后在此基础上进行修改即可,方便代码扩展。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
class BaseEmbeddings:
"""
Base class for embeddings
"""
def __init__(self, path : str, is_api : bool) -> None:
"""
初始化嵌入基类
Args:
path (str): 模型或数据的路径
is_api (bool): 是否使用API方式。True表示使用在线API服务,False表示使用本地模型
"""
self.path = path
self.is_api = is_api
def get_embedding(self, text : str, model : str) -> list[float]:
"""
获取文本的嵌入向量表示
Args:
text (str): 输入文本
model (str): 使用的模型名称
Returns:
List[float]: 文本的嵌入向量
Raises:
NotImplementedError: 该方法需要在子类中实现
"""
raise NotImplementedError # 如果子类没有实现该方法 会抛出异常
@classmethod
def cosine_similarity(cls, vector1 : list[float], vector2 : list[float]) -> float:
"""
计算两个向量之间的余弦相似度
Args:
vector1 (List[float]): 第一个向量
vector2 (List[float]): 第二个向量
Returns:
float: 两个向量的余弦相似度,范围在[-1,1]之间
"""
# 将输入列表转换为numpy数组,并指定数据类型为float32
v1 = np.array(vector1, dtype = np.float32)
v2 = np.array(vector2, dtype = np.float32)
# 检查向量中是否包含无穷大或 NaN 值
if not np.all(np.isfinite(v1)) or not np.all(np.isfinite(v2)):
return 0.0
dot_product = np.dot(v1, v2)
# L2 范数:所有元素的平方和的平方根
norm_v1 = np.linalg.norm(v1)
norm_v2 = np.linalg.norm(v2)
# 计算分母 两个向量范数的乘积
magnitude = norm_v1 * norm_v2
if magnitude == 0:
return 0.0
return dot_product / magnitude
- 创建一个兼容 OpenAI 调用办法的子类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class OpenAIEmbedding(BaseEmbeddings):
"""
class for OpenAI embeddings
"""
def __init__(self, path : str = '', is_api : bool = True) -> None:
super().__init__()
if self.is_api:
# 创建 self.client = OpenAI()
# 获取 api_key 与 URL
pass
def get_embedding(self, text, model):
if self.is_api:
text = text.replace("\n", " ")
return self.client.embeddings.create(input=[text], model=model).data[0].embedding
else:
raise NotImplementedError
@classmethod使方法绑定到类而非实例,可通过类名直接调用。
7.2.5 数据库与向量检索
- 设计一个向量数据库来存放文档片段和对应的向量表示,以及设计一个检索模块用于根据 Query 检索相关文档片段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class VectorStore:
def __init__(self, document: List[str] = ['']) -> None:
self.document = document
def get_vector(self, EmbeddingModel: BaseEmbeddings) -> List[List[float]]:
# 获得文档的向量表示
self.vectors = []
for doc in tqdm(self.document, desc="Calculating embeddings"):
self.vectors.append(EmbeddingModel.get_embedding(doc))
return self.vectors
def persist(self, path: str = 'storage'):
# 数据库持久化保存
if not os.path.exists(path):
os.makedirs(path)
with open(f"{path}/doecment.json", 'w', encoding='utf-8') as f:
json.dump(self.document, f, ensure_ascii=False)
if self.vectors:
with open(f"{path}/vectors.json", 'w', encoding='utf-8') as f:
json.dump(self.vectors, f)
def load_vector(self, path: str = 'storage'):
# 从本地加载数据库
with open(f"{path}/vectors.json", 'r', encoding='utf-8') as f:
self.vectors = json.load(f)
with open(f"{path}/doecment.json", 'r', encoding='utf-8') as f:
self.document = json.load(f)
def get_similarity(self, vector1: List[float], vector2: List[float]) -> float:
# 调用基类余弦相似度计算
return BaseEmbeddings.cosine_similarity(vector1, vector2)
def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:
# 根据问题检索相关文档片段
query_vector = EmbeddingModel.get_embedding(query)
result = np.array([self.get_similarity(query_vector, vector)
for vector in self.vectors])
return np.array(self.document)[result.argsort()[-k:][::-1]].tolist()
7.2.6 大模型模块
- 实现一个基类,方便其它模型扩展
1
2
3
4
5
6
7
8
9
class BaseModel:
def __init__(self, path : str = '' ) -> None:
self.path = path
def chat(self, prompt : str, history : list[dict], content : str) -> str:
pass
def load_model(self):
pass
- 调用样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
from openai import OpenAI
RAG_PROMPT_TEMPLATE="""
使用以上下文来回答用户的问题。如果你不知道答案,就说你不知道。
总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答数据库中没有这个内容,你不知道。
有用的回答:
"""
class OpenAIChat(BaseModel):
def __init__(self, model : str = "") -> None:
self.model = model
def chat(self, prompt : str, history : list[dict], content : str) -> str:
client = OpenAI()
# 获取 api key
# 获取 URL
history.append({'role': 'user', 'content': RAG_PROMPT_TEMPLATE.format(question=prompt, context=content)})
# response = client.chat.completions.create(
# model = self.model
# messages = history
# max_tokens = 2048
# temperature = 0.1
# )
# return response.choices[0].message.content
7.2.7 Demo 演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from VectorBase import VectorStore
from utils import ReadFiles
from LLM import OpenAIChat
from Embeddings import OpenAIEmbedding
# 没有保存数据库
docs = ReadFiles('./data').get_content(max_token_len=600, cover_content=150) # 获得data目录下的所有文件内容并分割
vector = VectorStore(docs)
embedding = OpenAIEmbedding() # 创建EmbeddingModel
vector.get_vector(EmbeddingModel=embedding)
vector.persist(path='storage') # 将向量和文档内容保存到storage目录下,下次再用就可以直接加载本地的数据库
# 保存了数据库
# vector = VectorStore()
# vector.load_vector('./storage') # 加载本地的数据库
question = 'RAG的原理是什么?'
content = vector.query(question, EmbeddingModel=embedding, k=1)[0]
chat = OpenAIChat(model='Qwen/Qwen2.5-32B-Instruct')
print(chat.chat(question, [], content))
7.3 Agent
7.3.1 什么是 LLM Agent
理解目标 -> 自主规划 -> 记忆 -> 工具使用 -> 反思与迭代
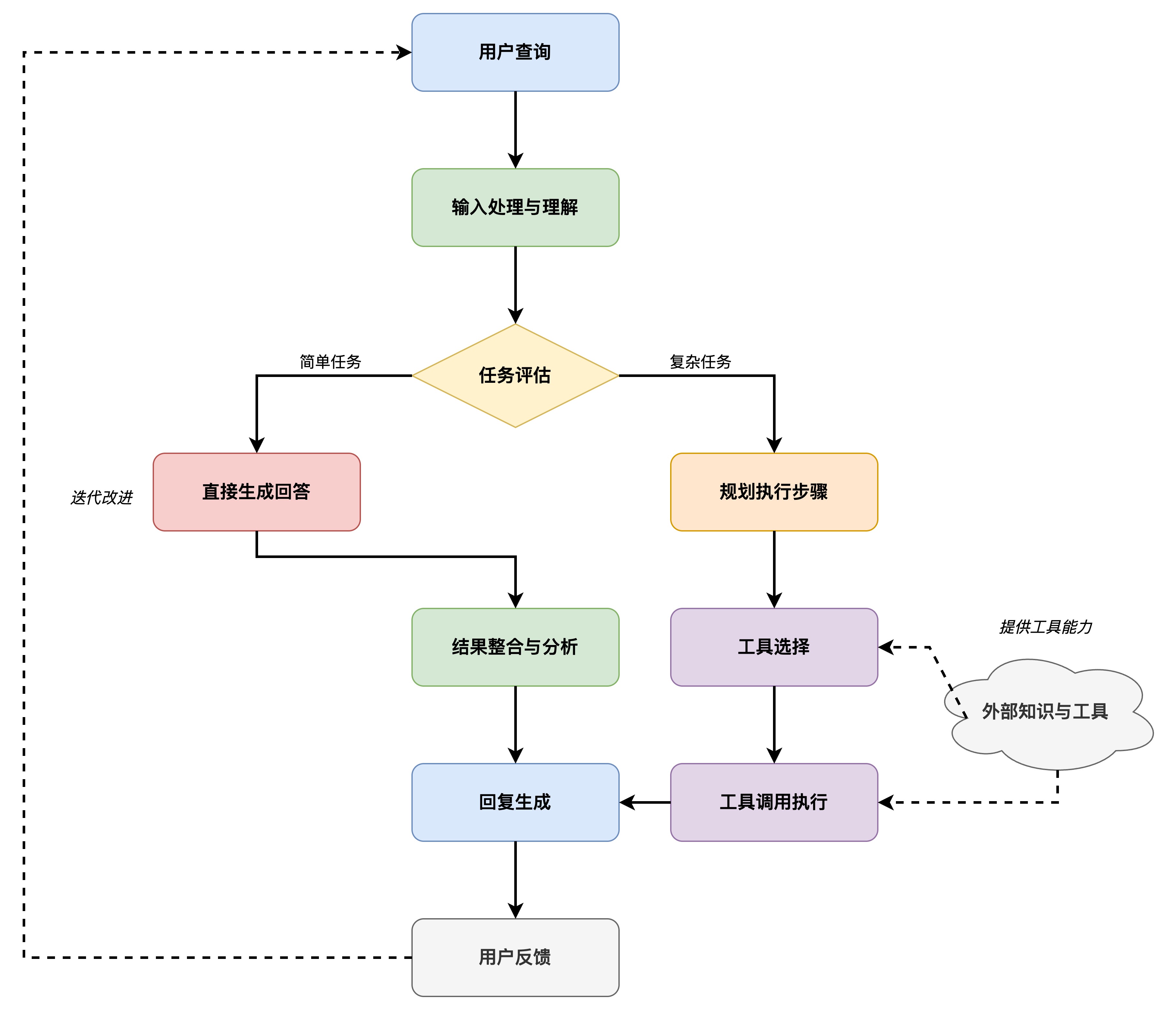
7.3.2 LLM Agent 的类型
任务导向型 Agent
规划与推理型 Agent
多 Agent 系统
探索与学习型 Agent
7.3.3 动手构建一个 Agent
设计工具函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from datetime import datetime
# 获取当前日期和时间
def get_current_datetime() -> str:
"""
获取当前日期和时间。
:return: 当前日期和时间的字符串表示。
"""
current_datetime = datetime.now()
formatted_datetime = current_datetime.strftime("%Y-%m-%d %H:%M:%S")
return formatted_datetime
def count_letter_in_string(a: str, b: str):
"""
统计字符串中某个字母的出现次数。
:param a: 要搜索的字符串。
:param b: 要统计的字母。
:return: 字母在字符串中出现的次数。
"""
return str(a.count(b))
# ... (可能还有其他工具函数)
- 为了让 OpenAI API 理解这些工具,我们需要将它们转换成特定的 JSON Schema 格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# src/utils.py (部分)
import inspect
def function_to_json(func) -> dict:
# ... (函数实现细节)
# 返回符合 OpenAI tool schema 的字典
return {
"type": "function",
"function": {
"name": func.__name__,
"description": inspect.getdoc(func),
"parameters": {
"type": "object",
"properties": parameters,
"required": required,
},
},
}
- 一个 Agent 类如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
class Agent:
def __init__(self, client: OpenAI, model: str = "Qwen/Qwen2.5-32B-Instruct", tools: List=[], verbose : bool = True):
self.client = client
self.tools = tools
self.model = model
self.messages = [
{"role": "system", "content": SYSREM_PROMPT},
]
self.verbose = verbose
def get_tool_schema(self) -> List[Dict[str, Any]]:
# 获取所有工具的 JSON 模式
return [function_to_json(tool) for tool in self.tools]
def handle_tool_call(self, tool_call):
# 处理工具调用
function_name = tool_call.function.name
function_args = tool_call.function.arguments
function_id = tool_call.id
function_call_content = eval(f"{function_name}(**{function_args})")
return {
"role": "tool",
"content": function_call_content,
"tool_call_id": function_id,
}
def get_completion(self, prompt) -> str:
self.messages.append({"role": "user", "content": prompt})
# 获取模型的完成响应
response = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
tools=self.get_tool_schema(),
stream=False,
)
# 检查模型是否调用了工具
if response.choices[0].message.tool_calls:
self.messages.append({"role": "assistant", "content": response.choices[0].message.content})
# 处理工具调用
tool_list = []
# 遍历所有的调用
for tool_call in response.choices[0].message.tool_calls:
# 处理工具调用并将结果添加到消息列表中
self.messages.append(self.handle_tool_call(tool_call))
tool_list.append([tool_call.function.name, tool_call.function.arguments])
if self.verbose:
print("调用工具:", response.choices[0].message.content, tool_list)
# 再次获取模型的完成响应,包含工具调用的结果
# 注意,这次把工具调用的结果也当作了输入
response = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
tools=self.get_tool_schema(),
stream=False,
)
# 将模型的完成响应添加到消息列表中
self.messages.append({"role": "assistant", "content": response.choices[0].message.content})
return response.choices[0].message.content