生成式AI時代下的機器學習(2025)
生成式AI時代下的機器學習(2025)
AI 技术突破与未来发展 PART - 第一讲
- 别急
AI agent PART - 第二讲
来源
AI agent 是什么?
- 传统:人类给予明确指令,一个口令对应 AI 一个动作
- AI agent:人类给予目标,AI 自己想办法达成
LLM-based agent 优势
- 传统:用 RL 来打造,但是只能针对一个任务,并且需要大量训练数据
- 现在:直接用 LLM,可以使用工具,无限可能
- 传统:RL 必须定义 Reward,reward 还需要调参(玄学)
- 现在:反馈更多,更容易修改
AI agent 例子
回合制互动
有一个 observation 就有一个 action
即时互动
action1 暂未结束,obs2 就来了,需要 agent 立刻停止 action1 转去执行 action2 (例如:带打断的语言通话)
AI agent 关键能力剖析
AI 如何根据经验调整行为
RAG(数据库是自我经验版):存在一个 Read 模组,只从 Agent’s Memory 中挑选出来与该 obs 相关的讯息来决策,从而避免一下子读很长很长的记忆
同时,存在一个 Write 模块,来决定 agent 要记录哪些事情,从而避免把一些鸡毛蒜皮的小事记录下来。一种实现方式是使用另一个 AI agent 充当 Write
还有一个 Reflection 模组,对记忆中的内容进行重新反思,抽象化思考,或许可以得到更好的思路。也可以建立一个 Knowledge Graph,以实现经验与经验之间更好的联系。一种实现方式是使用另一个 AI agent 充当 Reflection;
StreamBench benchmark:评测 agent 根据反馈修正自己行为的能力。得出反直觉结论:Negative feedback is unhelpful,与其告诉模型不要做什么,不如直接告诉模型要做什么
AI 如何使用工具
工具:只需要知道怎么使用,不需要知道内部运作原理;可以使用 RAG 作为工具,也可以把另一个模型当作工具
System Prompt: 教模型如何使用工具
如何使用所有工具:
把使用工具的指令放在 <tool> 与 </tool> 之间,输出放到 <output> 与 </output> 之间使用特定工具:
查询某地某时的温度的范式如下 Temperature(location, time),范例:Temperature('台北', '2025.02.22 14:26')其它:……
如果工具过多怎么办?不可能让 agent 读完所有的说明书后再来运行
故将说明书存入 memory 中
使用 Tool Selection 模块来选择
Agent 自己打造工具:
Make tools 后放到 memory 之中
AI agent 过度相信类似 RAG 的工具时也可能出错
AI agent 有一定的判断力
Internal Knowledge 与 External Knowledge 之间的抗衡
什么样的外部知识比较容易说服 AI:符合直觉的,外部知识与模型本身信念差距越大,模型就越不容易相信外部知识;模型对自身知识的信心也会影响是否选择外部知识;
相反的外部知识,模型选择哪个?:模型倾向于相信 AI 文章的话,而非人工创作,模型显然存在 bias
Meta Data 对模型选择的影响:AI 倾向于相信更新的文章;资料来源不影响选择;文章呈现方式影响倾向(例如,模板更好看的文章更容易获取 Claude 的信赖)
使用工具与模型本身能力的平衡
- 用工具并非总是有效率:简单计算,人和 AI 哪个快?
AI 能不能做计划
planbench: 评估大模型 plan 能力:上古时期论文,2023 年 LLM 难做到
- 有了 o1 后再次评测 planbench:LRM 有很大概率可以解决难题
TravelPlanner: 旅行计划 benchmark:大模型表现极差,犯错原因有:不符合常识;不符合预算要求……
- 使用现成 solver 去做 TravelPlanner:LLM 写一个程序,让这个程序去操控 solver,以规划出符合要求的旅行计划
怎么才能更合理地规划:
原始:DFS
进阶:带剪枝的 DFS,即模型自问自答,该分支是否有机会?低于某个阈值,就停止该路径
Tree Search for LM Agents:缺点明显,有些动作覆水难收,执行了就无法回溯
那就在模拟环境中搜索:需要一个 World Model,可以让 AI 自己充当一个 World Model,用来模拟环境,自行强化规划能力
AI 的腦科學 — 語言模型內部運作機制剖析 PART - 第三讲
来源
前置知识
你很熟悉 Transformer 的架构,可参考 【機器學習2021】(中文版)
可以翻回去看机器学习的可解释性课程(两节)
benchmark 评测
各大模型在 MMLU benchmark 评估结果:随着时间,显然表现更强;
很多实验结果是类比,测小模型,类比推断出大模型的结果;
一个神经元在做什么
相关性与因果性的不同
该神经元启动时,LLM 说脏话 - 只能是相关性;
移除该神经元,LLM 说不出脏话 - 也不能说因果,可能输出为 0 也影响了;
不同启动程度,LLM 说不同程度的脏话
类比人类大脑
川普神经元 - LLM 流行前的成果:输入跟川普有关的图片,有个神经元会启动;图片与川普关系越大,神经元启动程度越大;
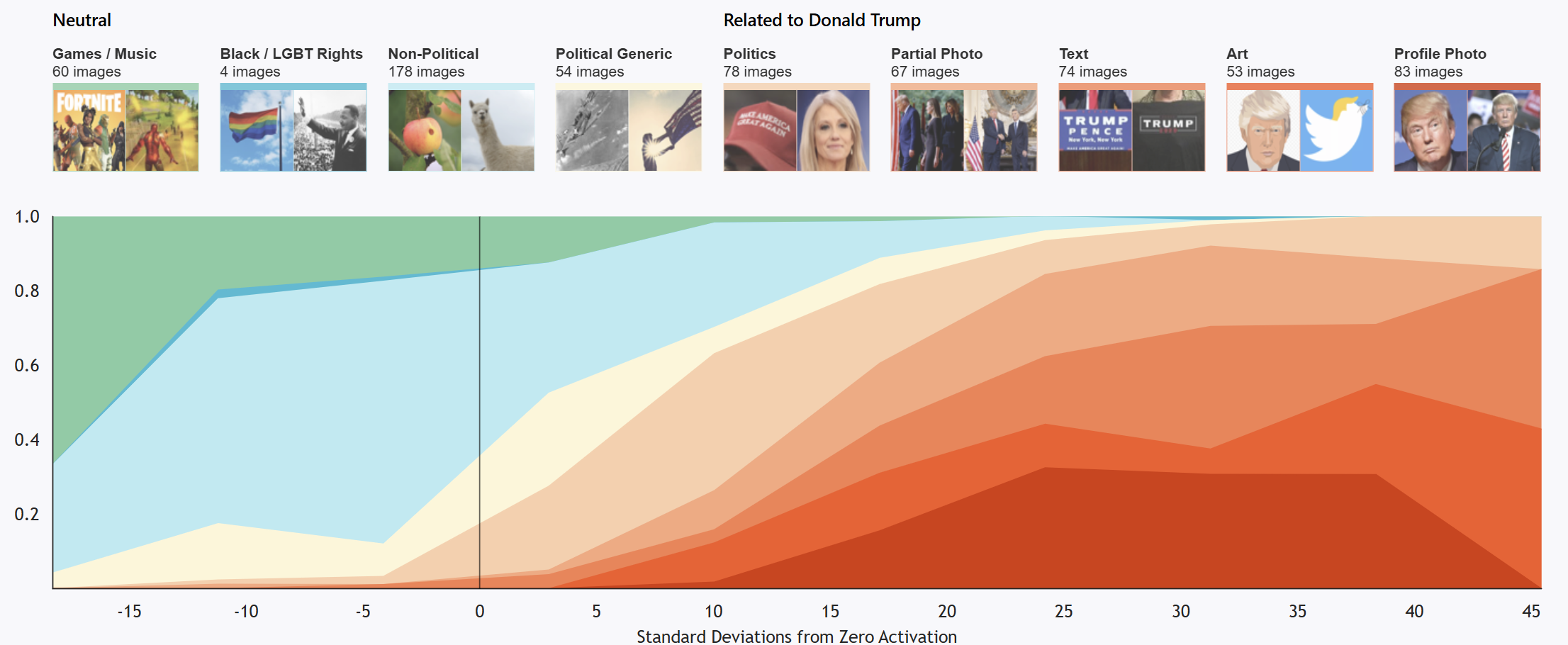
祖母神经元是一种虚构的神经元,认为有特定的神经元负责识别祖母;
一个神经元做不到什么,但是一群神经元可以做大事;
解释单一神经元功能
首先,不容易解释;
一件事情可能很多神经元管理,抹掉单一神经元,并不会严重影响 LLM 输出;
一个神经元可能同时管理很多事,研究
为什么不是一个神经元负责一个任务 - LLaMA 8B 一层只有 4096 个,那样子 LLM 能干的事情太少了;
可能是神经元组成一个个组别,由每组神经元负责任务,至少 2^4096 种可能性
一层神经元在做什么
一个假设:由一组神经元负责干某件事(例如存在一个负责拒绝的功能向量);
一层类神经网络的输出叫做 representation,对比 representation 与功能向量的相似性;
抽取拒绝向量
- 计算拒绝情况输入的 representation 平均与未拒绝情况输入的 representation 平均的差值,得到拒绝向量。
验证拒绝向量
把找到的拒绝向量塞入 representation 中,检查是否在不应该拒绝的话题中拒绝;
减去拒绝向量,检查是否在应该拒绝的话题中不拒绝;
每个论文的方法都可能不一样
找到了改变语言输出的功能向量,输出英文变成全输出中文;
上下文向量 01 论文;不是每一层找到的功能向量都有用;有些功能向量甚至可以进行向量加减,形成全新的功能向量;
可以使用 Sparse Auto-Encoder 来解出一个特定方程,找到功能向量
- 基于两个假设:
功能向量是一层层累加的结果;
每次选择的功能向量越少越好;
一群神经元在做什么
语言模型中的模型,模型是指用一个较为简单的东西来代表另一个东西:
要比原来的实物简单
保有原来实物的特征(faithfulness)
构建了一个抽取知识的模型:简化了模型,也检测了 faithfulness;同时试图在真实模型上检测构造的模型的 faithfulness。
- 例如有一个 Δx 对于构造的模型有用,那么把 Δx 加入到真实模型中,检查真实模型会不会显示出跟构造模型结果类似的结果。
系统化的语言模型的模型的建构方式:不断 pruning 神经元,直到一目了然;pruning 完的结果叫做 circuit。(network compression)
让语言模型直接输出想法
语言模型会说话,可以直接“问”,但是这显然不够深入。大模型真的理解自己怎么运行的吗?
语言模型的思维是透明的
不要忘记残差连接 residual connection
残差连接
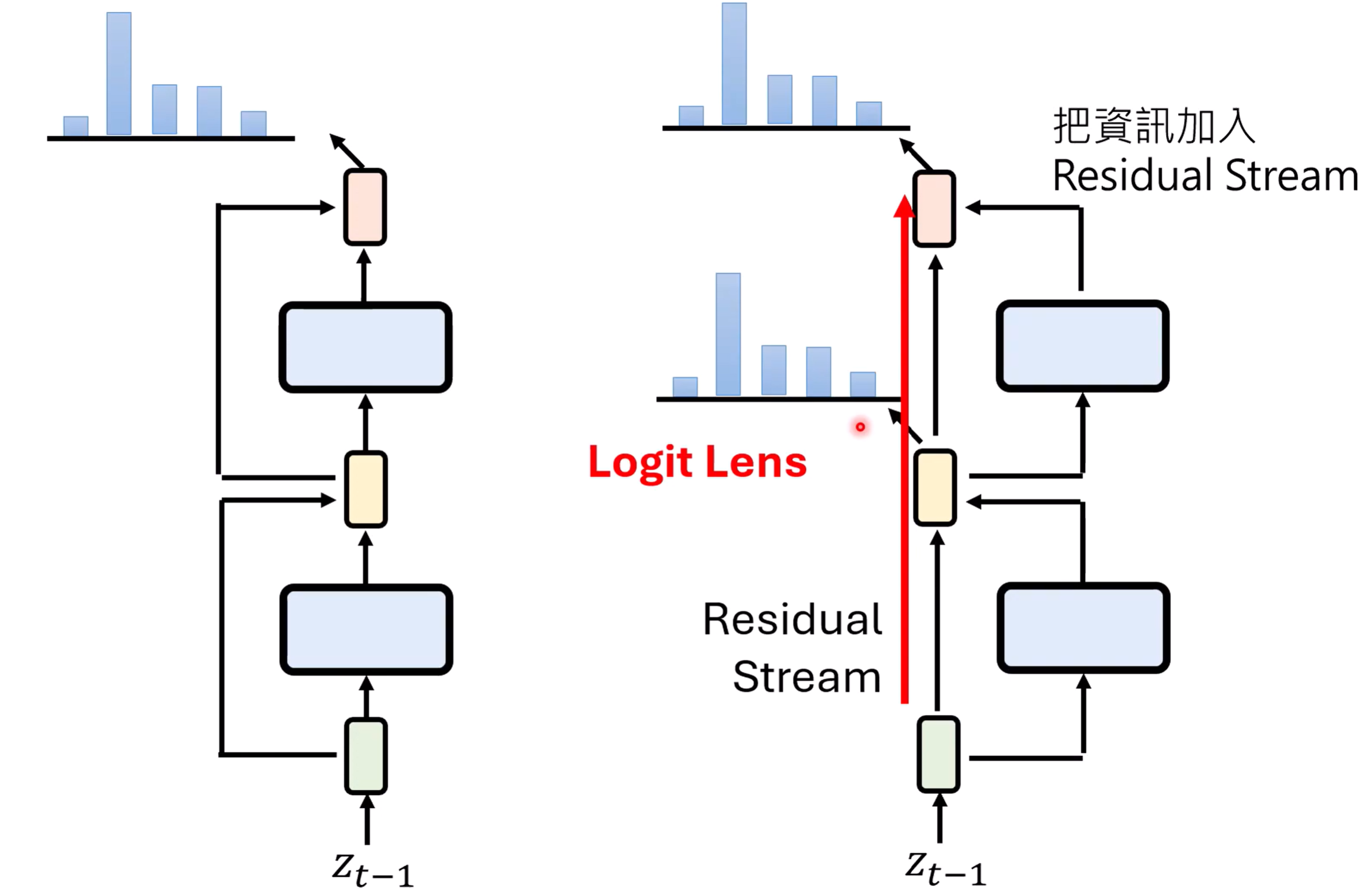
换个视角看残差,实际上残差连接像是一个高速公路:
Residual Stream:每一层都加一点什么进去
可以看一看上面这篇,有些难理解
大模型大部分是在预测下一个 token,logit lens 不一定能解析出来想要的结果。Patchscopes - 解析 LLM 每一层看到的东西是什么
对于 multi-hop 问题的解析 - Back Patching:有些结果必须在第 20 层才能解析出来,太深了。所以一个解决办法是,把后面的输出放到前面层中,再跑一次。这与 reasoning 模型“深度不够,长度来凑”的理念有异曲同工之妙。